聚石塔
订购TIS服务
登录至聚石塔首页(http://cloud.tmall.com),选择“产品与服务”下的“索引查询服务TIS”,点击马上使用申请免费试用.

审核通过后将通过手机短信、邮件、旺旺提醒等方式通知用户完成开通订购TIS服务.

TIS基本操作
管理TIS索引服务
登入聚石塔控制台,查看已经开通的TIS服务,在索引列表页面点击索引名称或点击右方的管理按钮,如未完成索引激活需先激活索引后进入索引管理页面.

索引基本信息
索引基本信息页面主要包含了索引的基本信息和索引数据源信息.

(1) 索引基本信息展示了当前索引的总文档数,总请求数,秒请求数以及错误数等信息.
(2) 索引数据源信息展示了当前索引的数据源类型、数据库名称、表名称、应用创建者以及应用创建时间等信息.
如果该应用的数据源地址发生了变更,可以点击“修改数据源”,更换数据源,将会重新进行索引创建,具体流程可以参考索引创建流程.
索引查询
索引查询允许用户自定义查询语句,对索引进行查询操作,点击索引查询页面按钮.

打开查询页面,查询页面支持任意组合的查询语句查询,还提供统计查询(facet)、分组查询(group)和高亮查询(highlight)三种高级查询,详细的查询语法.
元数据管理
元数据管理页面主要是在需要对元数据进行相关修改,或数据源字段发生变更,需要同步时使用.

元数据管理页面允许管理本对应的元数据信息,可以在本页面执行以下三种操作:
(1) 修改任何一个字段的任意属性;
(2) 点击同步数据源列信息,将同步数据源新增或删除的列信息;
(3) 点击添加按钮增加一个自定义的列;
以上三种操作,只有当你点击修改元数据并重新构建索引后才会生效.生效意味着:本次修改将替换之前的索引内容,同时服务端将重新构建索引,新索引会覆盖老的索引.
配额管理
该页面主要包含了索引创建过程中相关配额参数设置,如果业务场景有变更或数据规模以及访问量增加,当前的配额已经不满足实际需求,可以通过这个页面进行相关修改。点击修改,进行相关操作.

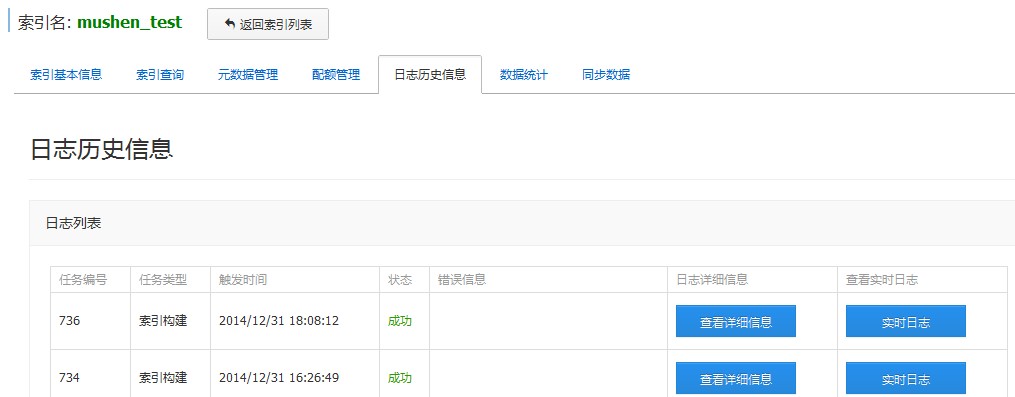
日志历史信息
日志历史信息页面主要是进行日志信息的管理,当激活索引弹出实时日志窗口后,关掉实时日常窗口,可以通过这个页面“查看详细信息”或者“实时日志”,状态栏如果是正在进行,表示索引正在创建,状态栏如果是完成,表示索引已成功激动,可在索引查询中测试索引服务.
数据统计
数据统计页面主要是进行索引数据的统计信息,主要统计索引的搜索次数(PV)和文档数据条数,提供多个时间维度的统计.
同步数据
当源数据每天有大量增量数据时,索引同步会导致出现索引碎片,影响查询性能;或者源数据发生了字段或者其它变更时,需要时同步数据页面。页面主要包括:定时索引重建,手动索引重建和索引构建历史.
源数据发生了字段或者其它变更时,需要选择手动创建,直接点击“手动索引重建”,将会重新创建一次索引,弹出实时日志窗口.

当源数据每天有大量增量数据时,索引同步会导致出现索引碎片,影响查询性能,这种情况可以选择定时重建索引,设置定时任务,比如每天0点50分构建一次全量索引.

创建TIS索引服务

索引命名:TIS可根据业务需要创建多个索引服务,同一个帐户下索引名称不能重复,索引名称以大小写字母开发,由字母和下划线组成,索引名长度4-20个字符.

选择数据类型和规模:TIS目前且支持RDS、ODPS数据源类型,后续将陆续支持DRDS和塔外数据类型.

选择数据源:列表中包含当前登陆帐号下所选数据源列表,根据业务场景将需要建索引的表结构添加到右边框,目前且支持多个DB下相同表结构数据导入.

定义SCHEMA:选择定义表结构中哪些字段需要建立索引,支持每个字段可搜索、可展示,区间查询等,同时支持用户自定义字段.
可搜索:勾选后此列数据可以被单独搜索,可搜索与可展示至少要选择一个;
可展示:勾选后搜索结果集将包含此列,同时索引数据量会急剧增加,建议查询中不需要返回的字段取消勾选此项,可搜索与可展示至少要选择一个;
区间查询:勾选支持区间查询,仅支持int或者long型字段的区间查询;
分词方法:字段类型为string的字段支持分词,其它类型不支持分词;
数据分组键:当数据量较大时,按所选分组将数据进行分库分表,该字段为后端系统必选项;
唯一性约束键:全局唯一键,表示此列数据不允许重复;

确认:提交并创建索引,创建成功后,需要激活索引才能正常使用.
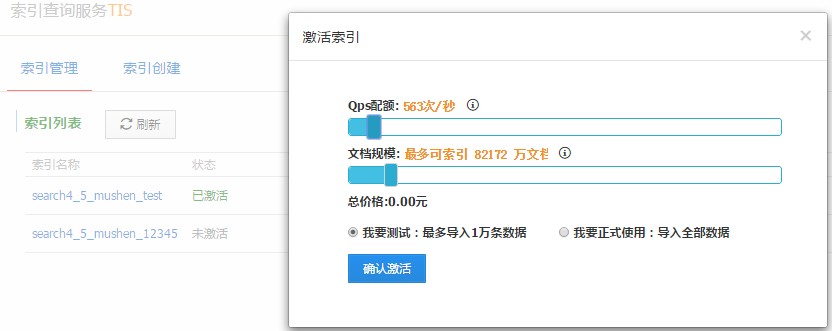
激活索引:选择该索引所需的资源配额,例如QPS和数据存储量,用户可根据业务需求选择测试使用和正式使用,测试使用最大支持10000条数据导入,正在使用会将该数据源表结构数据全部导入到TIS搜索引擎.
选择数据规模
点击激活,出现如下页面,用户需要选择导入全部数据还是最多导入一万条数据,一般情况下,如果是测试,建议选择最多导入一万条数据,保证资源的合理利用.
实时日志
确认激活后,会出现当前索引激活的实时日志,这个过程主要包括四个部分:(1)源数据导入;(2) 索引构建;(3) 索引切换;(4) TIS服务发布。页面上会展示出当前索引激活过程中的实时状态.
注意:数据源的数据量规模,决定了激活过程的时间长短,如果数据量很大的话,建议一段时间之后,再观察是否成功,或者直接关掉实时日志窗口,页面将进入当前索引的索引管理页面.
如何使用TIS
申请API权限
用户订购终端索引查询服务后,如需正式使用,需申请开通TIS终端索引查询服务API接口权限包,登陆开放平台控制台,在应用列表中点击进入应用详情,在证书权限管理中增值包申请选择相应权限包在线申请.

下载SDK
淘宝开放平台的SDK是由程序根据应用所拥有的API权限自动化生成的代码包,平台SDK支持的开发语言有java、.net、php 、python等四种,其它开发语言用户可基于HTTP协议自行封装,在下载生成SDK前,请先确认已申请开通了终端索引查询服务权限包.

API使用说明
索引查询使用TOP API接口,TOP作为淘宝数据插槽,只要用户按照TOP的规范拼装一个正确的URL,通过HTTP请求到TOP,就能够拿到用户自己需要的数据,索引查询 API <接口>采用 REST 风格,只需将所需参数拼装成http请求,即可调用.故支持 http 协议请求的程序语言,均可调用淘宝API, SDK示例代码如下:
Api说明: //open.taobao.com/apidoc/api.htm?path=cid:20626-apiId:24078
taobao.tis.query 调用示例(Java):
TaobaoClient client=new DefaultTaobaoClient(url, appkey, secret);
TisQueryRequest req=new TisQueryRequest();
req.setServiceName("search4wjb"); //索引名称
req.setQueryStr("q=title:xxx&routeValue=seller_id:4&start=0&rows=20"); //业务查询参数,根据商家业务场景自行拼装
TisQueryResponse response = client.execute(req);
taobao.tis.query 调用示例(PHP):
$c = new TopClient;
$c->appkey = appkey;
$c->secretKey = secret;
$req = new TisQueryRequest;
$req->setServiceName("search4wjb"); //索引名称
$req->setQueryStr("q=title:xxx&routeValue=seller_id:4&start=0&rows=20"); //业务查询参数,根据商家业务场景自行拼装
$resp = $c->execute($req);
taobao.tis.query 调用示例(.Net):
ITopClient client = new DefaultTopClient(url, appkey, appsecret);
TisQueryRequest req=new TisQueryRequest();
req.ServiceName = "search4wjb"; //索引名称
req.QueryStr = "q=title:xxx&routeValue=seller_id:4&start=0&rows=20";//业务查询参数,根据商家业务场景自行拼装
TisQueryResponse response = client.Execute(req);
查询语法说明
基本语法,":"在solr中指定字段查指定值.
场景:返回索引中所有的值; "name:小明", 返回索引中name字段为"小明"的所有记录.
对于分词的字段,首先会将查询语句中的查询条件分词,例如location:浙江杭州,分词器会将"浙江杭州"分词为"浙江"和"杭州",在索引中返回所有包含"浙江"和"杭州"的条目,两个词的逻辑关系和配置的defaultOperator的相关,具体见布尔查询.

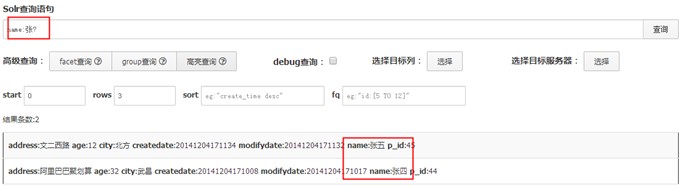
通配符查询,"?"表示单个任意字符的通配,"*"表示多个任意字符的通配.
说明:目前终搜使用的solr版本不能在检索的项开始使用*或者?符号,新版solr3.4已经支持起始端使用*.
场景:例如想查询标签前缀为"女"的条目,希望查询标签为"女鞋","女装","女包"所有的条目.
注意:通配符查询实际上是将query拆分成多个子句,例如查询词为“法*”,如果匹配成功很多“法律”、“法医”,会将所有匹配的doc取出取并集,比较消耗性能。在实际使用中需要限制模糊查询的条件,避免损耗太多性能.
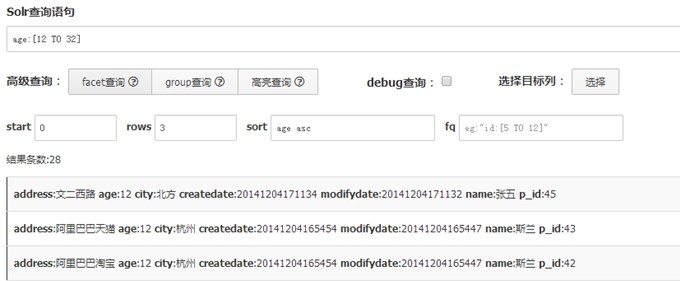
区间查询,区间查询支持任何数值类型,及date类型的查询,但出于查询效率的考虑,一般将date类型转为long类型.[] 包含范围检索,如检索某时间段记录,包含头尾,date:[200707 TO 200710],{} 不包含范围检索,如检索某时间段记录,不包含头尾.
场景:例如想查询时间为20130101到20131231时间范围内的交易信息,可以设定区间查询.
注意:区间查询相对普通的fieldName:value来说较为消耗性能,因为区间查询的本质是遍历区间域。例如price:[0 TO 10],那么会遍历price 0 到10,极端情况下要查10次,而field:value 查一次。通常不cache一次查询需要2次IO,区间查询消耗的查询是普通查询的数倍。如果区间查询是主要查询场景,那么请在元数据管理的时候选择是可范围查询或者请联系终搜答疑走区间查询的优化方法。 区间查询同通配符查询一样,会损耗较多性能,所以查询时应当控制上下限最大值和有效值。另外可以考虑使用fq缓存,将区间查询的结果保存在缓存中,减少磁盘IO,见fq查询 .
布尔查询,与操作符AND、&&,或操作符OR、||,排除操作符NOT、!、-,排除操作符排除包含指定term的文档,如address:(阿里 NOT 淘宝)选出address字段中包含“阿里”但不包含“淘宝”的条目.
场景:布尔查询支持多种逻辑运算符的组合,从而实现复杂查询.
注意:schema中有配置一项为defaultOperator,该项配置设定空格时的布尔逻辑,另外,该设定也影响分词时逻辑查询。为了保证查询逻辑清晰,不建议使用defaultOperator .

子查询,( ) 用于构成子查询,允许用户实现复杂的布尔逻辑.
注意:对于某个字段进行类似的操作,如“address:淘宝 阿里”的查询,实际上进行“address:淘宝 AND defaultSearchField:阿里”,在例子中defaultSearchField为p_id,类型不匹配报错。正确的写法为address:(淘宝 阿里),建议在进行布尔查询时加上()保证逻辑清晰.

转义操作符,对TIS中一些保留字符的查询需要进行转义,需要转义的字符包括以下字符。 “\” 转义操作符,特殊字符包括+ - && || ! ( ) { } [ ] ^ ” ~ * ? : \
场景:例如,需要查询value为-1的条目,需要对“-”进行转义,q=value:\-1.
常用查询参数说明
solr的查询语法,通过拼装查询语句,可以搜索得到满足查询条件的文档,查询语句都是放在q参数中,如“q= address:(淘宝 阿里) AND name:斯兰”。除此之外,solr还支持许多查询的优化方法、评分策略、展示方式等,这些都是通过设定solr查询参数实现的。在http请求中,不同的参数用“&”连接.
q,TIS中查询的基本参数,所有查询参数均会放在参数q中.
场景:例如q=item:iphone表示查询所有item中包含iphone的条目,参数q中可以放入更复杂的查询语法,详见TIS查询语法.
示例:
| …&q= item: iphone&… |
start,将初始偏移量指定到结果集中。可用于对结果进行分页。默认值为0,一般配合rows参数使用.
场景:start=15 返回从第 15 个结果开始的结果。 例如,一次查询命中100篇文档,但是返回时,是想返回30开始的15篇文档,此时start=30.
注意:如果start是动态传入,特别是页面传入,不能超过本身命中的最大文档数,同时不要执行大跨度的起始值,例如start=10000 这种参数的传入。因为start=1000时,是遍历到达1000,不是直接hash一步到位的.
示例:
| …&q= item: iphone&start=15&… |
rows,返回文档的最大数目。默认值为10,一般配合start参数使用.
场景:例如一个查询条件命中100条,但想返回15到20条,就可以通过设定start和rows参数,start=15&rows=5.
注意:大翻页的性能很低,如start=100000&rows=10,其实是查询了前100010条记录,尽量避免频繁操作.
示例:
| …&q= item: iphone&start=15&rows=5… |
sort,单域或者多域排序就是查询命中的文档,按照指定域的域值进行比较排序。多个域排序的时候,按照顺序当前一个域值相同的时候,选择下一个排序域,依次类推,通常来说2个域排序就够了。可以配合start和rows参数实现翻页
场景:例如想按照交易时间查询某个卖家的条目,可以通过设定参数sort=gmt_create desc;如果又想在返回结果按照买家id升序排列,设定参数sort=gmt_create desc,buyer_id asc,先按age升序,再按p_id降序
示例:
| …&q=seller_id:xxxxx&sort=gmt_create desc,buyer_id desc |
fl,作为逗号分隔的列表指定文档结果中应返回的 Field 集。默认为 “*”,指所有的字段。“score” 指还应返回记分.
场景:如查询时,只想返回买家id和卖家id,通过设定fl参数实现,fl=seller_id,buyer_id.
注意:根据需要返回查询域的列表可以减少网络传输,加速查询速度.
示例:
| …&q=*:*&fl=seller_id,buyer_id&… |
routeValue,分组路由值,Tis特有的参数,用于分组查询.
场景:比如数据按照seller_id进行分组,则查询的时候传参数routeValue=seller_id:123456,则查询的时候会定位到seller_id为123456的分组去查询,而不会每个分组都查询然后合并返回,性能会好很多.
示例:
| …&q=*:*&routeValue=seller_id&… |
fq,提供一个可选的筛选器查询。查询结果被限制为仅搜索筛选器查询返回的结果。筛选过的查询由 Solr 进行缓存.它们对提高复杂查询的速度非常有用,对于任何经常查询的查询条件均可以放入到fq查询中.
场景:例如经常会查询date_time是20081001到20091031之间的条目,就可以在fq中配置查询条件fq=date_time:[20081001 TO 20091031].
注意:fq走的是缓存查询,所以使用fq不开启相关cache或者cache参数配置不合理,均达不到很好的响应效果.但是如果增量更新较大,每次更新会重置fq缓存,fq查询不会起到很好的作用.
示例:
| …&q=seller_id:xxxx&fq=date_time:[20081001 TO 20091031]&… |
facet,根据查询条件命中的文档,对这一批命中的文档按照给定的域进行进行统计。例如查询条件为*:*,返回44条结果,将这44条结果按照city域统计,得到该域所有不同的条目出现的次数.
场景:facet查询能够统计查询条件命中结果的个数.
注意:如果查询中facet 没有反应,那说明要么是solrconfig 中没有启用facet 这个component 或者命中的文档中,facet 域值是空的。facet查询是比较消耗性能的,请注意优化.
示例:
facet=ture表示开启facet.
facet.field=city表示统计city域的次数,如果需要统计多个域,需要加入多个facet.field.
facet.offset和facet.limit与start和rows类似,实现facet的翻页功能.
facet.mincount限制显示对应条目统计次数的最小值.
facet.prefix限制显示匹配对应前缀的条目.
| …&q=*:*&facet=ture&facet.field=city&facet.limit=3&facet.offset=0&facet.mincount=1&… |
group,指定域进行结果集的分组,类似数据库的group 概念,语法与facet类似.
示例:
group=true表示group查询开启.
group.field=city指定group的域.
group.limit=3&group.offset=0实现组内翻页.
group.sort=p_id desc指定组内排序.
rows=3指定显示分组的个数.
| …&q=address:阿里&group=ture&group.field=city&group.limit=3&group.offset=0&group.sort=p_id desc&rows=3&sort=p_id asc&… |
