聚石塔
1.概述
聚石塔性能测试服务(Performance Testing Service,简称PTS)是集测试机管理、测试数据管理、测试脚本管理、测试场景管理、测试任务管理、测试结果管理、缺陷管理为一体的性能自动化测试平台。有别于以往传统的压测工具,PTS具备分布式高并发压测、脚本在线编辑调试、任务定时启动停止、结果实时展示并持久化保存等特点。针对塔内用户复杂的分布式应用,PTS可以快速扩容动态配置域名,满足不断增长的集群压测需求。
2.性能指标介绍
以下是在使用PTS的过程中会遇到的性能指标含义,这些指标决定了该应用的性能水平,同时是定位性能瓶颈的依赖条件。
2.1.业务指标
2.1.1.事务
事务是性能测试脚本的一个重要特性,要度量服务器的性能需要定义事务,每个事务都包含事务开始和事务结束标记。事务用来衡量脚本中一行代码或多行代码执行所耗费的时间。可以将事务开始放置在脚本中某行或者多行代码的前面,将事务结束放置在该行或者多行代码的后面,在该脚本的虚拟用户运行时此事务将衡量该行或者多行代码的执行花费了多长时间。
2.1.2.TPS
TPS(Transaction Per Second)每秒系统能够处理的交易或事务的数量,它是衡量系统处理能力的重要指标。
2.1.3.并发
并发分为狭义和广义两类。
狭义并发即所有的用户在同一时刻做同一件事情或操作,这种操作一般针对同一类型的业务,或者所有用户进行完全一样的操作,目的是测试数据库和程序对并发操作的处理。
广义并发即多个用户对系统发出了请求或者进行了操作,但是这些请求或操作可以是不同的,但对整个系统而言,仍然是有很多用户在同时进行操作。
狭义并发强调对系统的请求操作是完全相同的,多适用于负载测试、压力测试;广义并发不限制对系统的请求操作,多适用于混合场景、稳定性测试。
2.1.4.Scenario场景
性能测试过程中为了模拟真实用户的业务处理过程,在系统中构建的基于事务、脚本、虚拟用户、运行设置、运行计划、监控、分析等一系列动作的集合称之为性能测试场景。场景中包含了待执行脚本、脚本组、并发用户数、负载生成器、测试目标、测试执行时的配置条件等。
2.1.5.Response Time响应时间
响应时间是指从客户端发一个请求开始,到客户端接收到服务端返回的响应所经历的时间,响应时间由请求发送时间、网络传输时间和服务器处理时间三部分组成。
在性能测试结果分析中,性能场景中事务的响应时间可以通过监控得到,事务响应时间分为事务最小响应时间、事务平均响应时间、事务最大响应时间。
2.1.6.虚拟用户数
模拟真实业务逻辑步骤的虚拟用户,虚拟用户模拟的操作步骤都被记录在虚拟用户脚本里,脚本用于描述用户在场景中执行的操作。
2.1.7.请求状态
请求状态反映了HTTP压测结果的HTTP状态码,状态码含义如下:
成功200:服务器已成功处理了请求并提供了请求的网页。
成功204:服务器成功处理了请求,但没有返回任何内容。
重定向3xx:每次请求中使用重定向不要超过5次。
客户端错误4xx:表示请求可能出错,妨碍了服务器的处理。
服务器错误5xx:表示服务器在处理请求时发生内部错误,这些错误可能是服务器本身的错误而不是请求出错。
2.1.8.CPU
CPU资源是指性能测试场景运行的时间段内应用服务系统的CPU资源占用率,CPU资源是判断系统处理能力及应用运行是否稳定的重要参数。应用服务系统可以包括应用服务器、Web服务器、数据库服务器等。
2.1.9.Load
系统平均负载指在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件就会位于运行队列中:
- 它没有在等待I/O操作的结果。
- 它没有主动进入等待状态,也就是没有调用“wait”。
- 没有被停止,例如等待终止。
2.1.10.磁盘使用
用于表明服务器磁盘使用比例。
3.使用流程
3.1.概览

一套完整的的性能测试过程如上图所示,包括测定环境管理、脚本创建、场景创建、任务创建、任务执行和结果查看。
脚本是执行性能测试的基础,脚本里包括需要压测的服务器地址、压测的url、压测的参数和压测的类型。
场景需要绑定脚本来运行,一个场景绑定一个脚本,可在场景中设置并发压测用户数、施压模式。
任务执行需要绑定场景,一个任务可以绑定多个场景,任务开始执行后可以实时查看性能指标。
结果自动保存可随时查看。
3.2.环境管理
PTS产品购买并生产完之后,从控制台进入PTS测试环境节点下,显示默认规格的测试服务器ECS和RDS,点击‘管理’可进行服务器的配置,与云主机和云数据库配置操作完全一样。

3.3.性能脚本编写
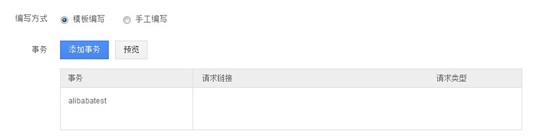
3.3.1.模版编写
如选择模板编写脚本,首先需创建事务,事务名可根据实际业务制定,如图所示:
然后可添加待测系统链接,同时可选择Http请求类型(GET或POST),如图所示:
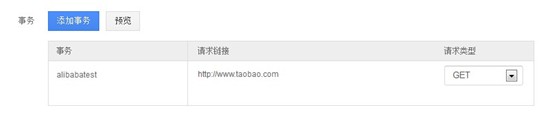
请求类型如选择的是GET方式,直接输入待测系统链接地址即可;如选择的是POST方式,需要对待测系统链接地址进行拼接,拼接步骤如下:
- 用抓包工具(例如Firebug)捕获待测系统的POST请求,如图所示:

- 查找POST请求主体,如图所示:

- 把POST请求主体拼接在待测系统链接地址后面,用“?”连接,拼接完成后输入到请求链接中,如图所示:

一个脚本里可以包含多个事务,一个事务里可以包含多个链接,事务与链接的顺序可调整,脚本执行时会按顺序执行所有事务与链接。
注意:用户只能针对服务开通时分配到的ECS进行性能测试,所有压测请求都会指向此台ECS。
3.3.2.手工编写
PTS提供脚本在线开发环境,如模板编写不能满足需要可直接在此环境里开发脚本,同时可在线调试脚本,调试过程不超过30秒,如果脚本在执行30秒后还没有返回系统会自动终止调试进程。
PTS采用的脚本语言为Jython,目前支持的Jython版本为2.2.1。Jython是Python的Java语言实现,它使用Python的语法和类库,运行在JVM中,和同一个JVM中的Java类可以实现无缝互操作,因此使用Jython作为脚本语言可以最大程度的利用Python的简洁、高效,同时保留对Java语言的全面兼容。
本章重点介绍与编写性能测试脚本相关的Jython语言基础,内容有限,读者如果需要更全面深入地理解Jython语言可以参考Python的Tutorial和Jython的用户手册。
- Jython词法
Jython程序由一系列语句组成,语句组成了代码块,代码块组成了方法、函数,然后再通过类把数据、方法和函数封装起来。和其它高级语言一样,Jython的语句也是由一些最基本的词(token)组成。Token可以是标识符(identifiers)、关键字(keywords)、字面值(literals)、操作符(operators)和分割符(delimiters),这些token通过Jython的语言执行器进行词法分析产生,而词法分析器通过字符方式读入Jython脚本文件,这时会涉及到文件编码问题。
- 文件编码
Jython默认以ASCII码(Latin-1)的方式读入脚本文件,如果你的文件中存在非7位ASCII编码的字符就会发生错误。我们通过在脚本文件首行添加以下代码来让Jython分析器知道用那种编码来读入脚本文件:
# -*- coding: utf-8 -*-
以上指示表示该Jython脚本的编码为UTF-8,这样我们就可以在脚本中使用中文这样的Unicode字符。
- 代码行
Jython脚本由逻辑代码行组成,逻辑行可以是一个物理行也可以是多个物理行通过显式或隐式连接起来的,物理行就是文件中以NEWLINE结尾的行,NEWLINE在不同的平台上有所不同,比如UNIX系统中以LF(linefeed)作为换行,Windows中以(CRLF)作为换行,Mac中以CR作为换行,这些换行符在Jython中都支持。
显示连接用在一行语句太长需要分多行显示的情况,我们可以通过“\”将多行连接成一条语句:
if 1900 < year < 2100 and 1 <= month <= 12 \
and 1 <= day <= 31 and 0 <= hour < 24 \
and 0 <= minute < 60 and 0 <= second < 60: # Looks like a valid date
return 1
隐式连接是指当我们用小括号、中括号或者大括号声明的数据可以分多行写,不需要使用反斜杠来连接:
month_names = ['Januari', 'Februari', 'Maart', # These are the
'April', 'Mei', 'Juni', # Dutch names
'Juli', 'Augustus', 'September', # for the months
'Oktober', 'November', 'December'] # of the year
- 代码块
代码块可以是一个类,一个方法/函数,或者是一个if/while的控制单元。多数程序语言会用专门的开始结束标志来表示一个代码块,但是Jython/Python却通过缩进来表示一个代码块,这是初学Python的人最不适应的地方。缩进可以使用空格或者Tab制表符,但是最后Jython在解析的时候会将Tab转换成空格,而不同的机器Tab和空格的对应关系可能不一样,比如Windows通常使用4个空格表示一个Tab,而Unix可能用8个空格。所以非常重要的是我们在编辑器中只使用一种缩进方式,要不都用空格,要不都用缩进。开启一个代码块需要用‘:’来提示。
def perm(l):
# Compute the list of all permutations of l
if len(l) <= 1:
return [l]
r = []
for i in range(len(l)):
s = l[:i] + l[i+1:]
p = perm(s)
for x in p:
r.append(l[i:i+1] + x)
return r
- 标识符
Jython的标识符(类名、变量名等)只能以下划线或者字母开头,后面跟字母、数字或者下划线,其他任何字符都是非法的标识符。标识符区分大小写。
- 类和方法
用户可以定义一个类把数据和操作封装起来。比如下面这段代码定义了一个TestRunner的类,这个类有4个方法:__init__、__call__、__del__和transaction。Jython定义方法用到关键字def,一般”__*__”格式的方法都是语言内置的特殊方法。__init__方法是类的初始化方法,当类被实例化的时候该方法会被用调用来初始化类的成员数据。__call__方法用来实现类的callable接口,一般会在多线程调用时用到,同时用来放置测试的业务主体,这样可以多次循环的调用业务逻辑。__del__方法类似Java的finalize方法,通常在类的对象消亡之前执行一些销毁操作,但并不是实时。
class TestRunner:
def __init__(self):
self.word = '中文'
def transaction(self, arg1, arg2):
print arg1, arg2
statusCode = [0L, 0L, 0L, 0L]
result = HTTPRequest().GET('http://www.baidu.com/s', \
[ NVPair('wd', '中文'.decode('UTF-8')), ])
Trunner.addHttpCode(result.getStatusCode(), statusCode)
return statusCode
def __call__(self):
grinder.statistics.delayReports = 1
statusCode = self.transaction()
Trunner.setExtraData(statusCode)
grinder.statistics.report()
grinder.statistics.delayReports = 0
def __del__(self):
self.word = 'None'
通过上面这段代码我们可以发现Jython与Java或C这些强类型语言的一些区别,变量的申明不需要指定类型,同样方法或者函数的入参和返回值也不需要指定类型,这就是Jython/Python语言的另一大特性——弱类型,Jython执行器只有在执行的时候才回去判断对象的类型,如果有不匹配的操作会抛出异常。
此外self类似Java语言中的this,通过self类中的方法/函数可以引用类的成员变量或者调用类的成员方法,如果不加self则默认使用全局空间的变量或方法,所谓全局变量/方法就是定义在类之外脚本中顶格写的变量或者方法。定义类成员函数时,必须把self作为第一个参数传递给所定义的方法。
- 脚本的执行
Jython是解释执行语言,所以一个脚本被Jython引擎分析后是按行执行的,脚本中顶格的代码行都是会被执行器执行的,而类或者全局方法则会被定义,定义之后代码中其他的地方可以使用这些类和方法。
一般脚本的前几行都是用来注释和作指引(比如字符编码):
#! /usr/bin/env python
# -*- coding: utf-8 -*-
接下去会有一些import语句来导入脚本中所用的其它类或者模块,Jython中的模块(Module)类似Java中的Package,用来把一组功能耦合的类封装在一起,同时也可以直接导入Java的package或者类。比如:
#导入Jython类库
import sys
import encoding
#导入Java的标准类
from java.lang import String
from java.nio.charset import Charset;
#导入用户写的类
from net.grinder.script.Grinder import grinder
from net.grinder.script import Test
#导入用户写的Jython类
from util import Trunner
可以在脚本中定义一些类或者方法:
class TestRunner:
def tran1_4478(self):
……
也可以执行一些语句:
connectionDefaults = HTTPPluginControl.getConnectionDefaults()
httpUtilities = HTTPPluginControl.getHTTPUtilities()
connectionDefaults.setFollowRedirects(True)
connectionDefaults.setEncoding('GBK')
connectionDefaults.setProxyServer('localhost', 8888)
TrunnerContext.getContext().setParamDirectory("D:/trunner/data")
params = ParamManager.getInstance()
- 常用类和语法
在使用Jython编写程序时变量不需要声明可以直接使用,创建对象也不需要向Java一样使用new关键字,直接使用类名传入初始化参数就行,比如:
log_file = FileOutputStream(‘/tmp/test.log’)
- 字符串
Jython中的字符串是通过单引号、双引号注明的字符集,单引号注明的字符串中可以包含双引号而不需要用转义,同样双引号中的单引号也不需要转义。比如:
s = ‘This is a “BIG” surprise!’#这是一个合法的字符串
字符串作为一种特殊的字符数组支持下标操作,比如:
s[0]=’T’
s[0:5]=’This’
- 列表
Jython中用[]来表示一个列表,列表是可变的,比如:
a = [‘apple’, ‘orange’, ‘peach’]
数组下标从0开始:
a[0]=’apple’
a[1]=’orange’
获取列表长度用Jython内置函数len,比如:
len(a)=3
- HTTP请求对象
所有HTTP请求都是通过调用HTTPRequest类的方法完成:
from HTTPClient import NVPair
from net.grinder.plugin.http import HTTPRequest
result = HTTPRequest().GET('http://www.baidu.com/s', [ NVPair('wd', '中文'.decode('UTF-8')), ])
- 设置HTTP请求的头
可以通过HTTPRequest的setHeaders方法设置自定义的HTTP请求头:
headers = [NVPair('Accept-Encoding', 'gzip'), \
NVPair('Accept', 'text/html'), \
NVPair('User-Agent' , 'Mozilla/5.0 (Windows NT 6.1)')
]
request = HTTPRequest()
request.setHeaders(headers)
- 设置HTTP请求的链接属性
from net.grinder.plugin.http import HTTPPluginControl
#获得连接默认设置对象
connectionDefaults = HTTPPluginControl.getConnectionDefaults()
#将连接默认设置成自动跟踪HTTP的跳转指令(StatusCode:30X)
connectionDefaults.setFollowRedirects(True)
#将请求发送的流设置成GBK编码方式
connectionDefaults.setEncoding('GBK')
- HTTP响应对象
通过HTTP的GET或者POST请求会得到HTTPResponse对象,此对象封装了HTTP的响应信息,包括响应头、响应主体,通过HTTPResponse的getText或者getData方法可以获得返回的HTTP响应体,前者以字符串方式返回,后者以字节数组返回。
- HTTP的Cookie模块
from HTTPClient import CookieModule
from HTTPClient import Cookie
from java.util import Date
expiryDate = Date()
expiryDate.year += 10
cookie = Cookie("user_ark_cookie", "3abfe8db9d975c9a77abe764a889641a633bec14d6c19a81e9a088ed8ce19247ab2f99459b6529bc831dcb30e7a08a4aa614a43f6dfbf7dda5f2c034935466231252bd5203e14d214196159a11225613","/", expiryDate, 0)
CookieModule.addCookie(cookie, self.threadContext)
- Trunner支持类
用户可以使用Jython标准库、Java标准库的同时,PTS将一些常用的功能包装在Trunner这个类中,用户可以使用Trunner静态方法来完成一些功能。
保存HTTP响应结果,该功能建议只在调试脚本的时候使用,否则会生成过多的HTTP返回文件。
result = HTTPRequest().GET('http://www.taobao.com/s', \
[ NVPair('wd', '中文'.decode('UTF-8')), ])
Trunner.save(result)
在HTTP返回中查找目标串。
result = HTTPRequest().GET('http://www.taobao.com/s', \
[ NVPair('wd', '中文'.decode('UTF-8')), ])
- Instrument被测方法
如果我们需要对脚本中的某个方法或者Java类的某个方法进行性能测试,我们需要对这些类和方法进行Instrument。如果使用模板生成的脚本,系统会自动在脚本末尾加上对模板中定义的transaction进行instrument的语句。如果使用手工编写则需要自行添加instrument语句进行性能测试:
Trunner.instrumentMethod(Test(4478, 'tran1'), 'tran1_4478', TestRunner)
#生成一个用来计时的测试对象,4478为transaction的ID;tran1为前端展示用的transaction名称;
#'tran1_4478'是需要instrument的方法名称;
#TestRunner是需要instrument的类名称。
如果是模板编写,transaction的ID由系统自动产生。如果是手工编写,需要调用接口为transaction生成一个唯一ID:
Trunner.instrumentMethod(Test(PapClient.getId(1334, 'page1'), 'page1'), 'page1', TestRunner)
上面这行代码为TestRunner的page1方法产生了一个Test对象,对象ID是通过PapClient.getId(1334, ‘page1’)来获得,Test的描述是’page1’。PapClient.getId方法接受两个参数,脚本ID和transaction名称,可以通过脚本列表查看脚本ID。
- 脚本框架
PTS的性能测试脚本是一个TestRunner类,这个类会被每一个并发线程初始化。测试进程首先加载脚本并执行脚本中顶格的语句,同时定义TestRunner这个测试类。然后每个线程会实例化一个TestRunner类,调用类中的__init__方法一次,继而循环调用TestRunner类的__call__方法。最后线程结束时会调用类中的__del__方法。__init__和__del__方法都是可选的,只有__call__方法是必需的。
第一部分:执行器声明和脚本编码声明
#! /usr/bin/env python
# -*- coding: utf-8 -*-
第二部分:Jython类库、Java类库和自定义类的导入
from java.lang import String
from java.nio.charset import Charset;
from net.grinder.script.Grinder import grinder
from net.grinder.script import Test
from util import Trunner
…………
第三部分:测试进程级别的脚本语句和初始化
connectionDefaults = HTTPPluginControl.getConnectionDefaults()
httpUtilities = HTTPPluginControl.getHTTPUtilities()
params = ParamManager.getInstance()
params.addProvider(DsvReader('words.txt'))
第四部分:TestRunner测试类
def __init__(self) #方法中编写每个线程需要执行一次的操作,比如登录
def __call__(self) #方法中编写需要压力测试的主体业务逻辑
def __del__(self) #方法中编写测试线程结束时需要执行的操作
……………………… #其他方法中编写待测逻辑,一个方法可以作为一个transaction
第五部分:Instrument语句
Trunner.instrumentMethod(Test(4478, 'tran1'), 'tran1_4478', TestRunner)
Trunner.instrumentMethod(Test(PapClient.getId(1334, 'page1'), 'page1'), 'page1', TestRunner)
- 脚本举例
用户自定义登录:
class TestRunner:
def __init__(self):
#用户登录一次
self.login('password')
self.threadContext = HTTPPluginControl.getThreadHTTPClientContext()
#将登录后的cookie保存起来供后面的调用使用
self.login_cookies = CookieModule.listAllCookies(self.threadContext)
def login(self, password):
HTTPRequest().POST('https://login.taobao.com/member/login.jhtml', \
[ NVPair('TPL_username', '用户名'.decode('UTF-8')),
NVPair('TPL_password', password),
NVPair('miniLogin', 'false'),
NVPair('TPL_checkcode', ''),
NVPair('need_check_code', ''),
NVPair('_tb_token_=', '755b5e3e1ee76'),
NVPair('action', 'Authenticator'),
NVPair('event_submit_do_login', 'anything'),
NVPair('TPL_redirect_url', ''),
NVPair('from', 'tb'), ])
def __call__(self):
#由于每次__call__循环结束cookie被清空,所以需要手动添加
for c in self.login_cookies:
CookieModule.addCookie(c, self.threadContext)
HTTPRequest().GET('http://trade.taobao.com/trade/itemlist/list_bought_items.htm')
关联前一个页面读取数据:
class TestRunner:
def __call__(self):
self.buynow()
encryptString = httpUtilities.valueFromHiddenInput("encryptString")
seq = httpUtilities.valueFromHiddenInput("13067687:2|seq")
sid = httpUtilities.valueFromHiddenInput("sid")
token = httpUtilities.valueFromHiddenInput("_tb_token_")
gmtCreate = httpUtilities.valueFromHiddenInput("gmtCreate")
#或者
result = self.buynow()
#从返回页面中找到encryptString和13067687:2|seq之间的字符串
encryptString = Trunner.findVar(result.getText(),"encryptString", \
"13067687:2|seq"
参数使用随机或者顺序的数字:
from com.taobao.qa.perf.tr.data import SequenceParamImpl
#起始数字,终止数字,间隔
seqList = SequenceParamImpl("seqList", 14621233003, 94621229010, 1)
seq = seqList.next()
#数字转字符
queryString = "itemId=" + str(seq)
脚本中实现事务的并行执行:
from java.util import Random
class TestRunner:
def __init__(self):
self.rn = Random() #初始化
def __call__(self): #实现事务调用
d = self.rn.nextDouble()
if d < 0.33:
事务1
elif d < 0.67:
事务2
else:
事务3
脚本中实现json解析:
# 脚本文件顶部引入以下三个类
from com.alibaba.fastjson import JSON
from com.alibaba.fastjson import JSONObject
from com.alibaba.fastjson import JSONArray
str='{"data":{"$isWrapper":true,"data":[{"trade_create_time":"2014-10-11T21:00:10Z","print_time":null,"tp_total":350.0,"tp_post_fee":0.0,"tp_payment":350.0,"gx_payment":0.0,
"pay_money":0.0,"tp_logistics_type":9,"print_express":0,"print_invoice":0,"print_cargo":0,"tp_status":2,
"tp_has_refund":0,"salercpt_uid":"D8F3894746A63845A0176197A8428B07","salercpt_no":"XD14102900002",
"tp_tid":"14631495442220979","shop_nick":"BV","delivery_uid":"3E1495E1FBCB3A75866C18478690E1AE",
"delivery_name":"EMS","express_uid":null,"tp_buyer":"sandbox\u9057\u5FD8\u5C18","tp_message":null,
"tp_receiver_name":"sandbox\u9057\u5FD8\u5C18","tp_receiver_state":"\u6D59\u6C5F\u7701",
"tp_receiver_city":"\u676D\u5DDE\u5E02","tp_receiver_district":"\u897F\u6E56\u533A",
"tp_receiver_address":"\u6D59\u6C5F\u7701,\u676D\u5DDE\u5E02,\u897F\u6E56\u533A,
\u534E\u661F\u8DEF491\u53F7\u521B\u4E1A\u5927\u53A614631495442222979,310019",
"tp_receiver_zip":"310019","tp_receiver_mobile":"15869555555","tp_receiver_phone":"0571-88155188",
"print_remark":null,"sys_shop":"8530F2405F1811E4BCE3AC853DAE840C","tp_type":1,"exchange_state":0,
"exchange_label":null,"weight":0.0,"trade_status":0,"sums":2,
"custom_code":"F637DF2370753CD4AB7475F092E1FC05","merge":null,
"tp_pay_time ":"2014-10-11T21:01:00Z","bill_type":1,"remark":null,
"tp_memo":"RDS\u6027\u80FD\u6D4B\u8BD5\u5907\u6CE8",
"send_goods_time":"2014-10-11T23:33:11Z","passedTime":"18\u592919\u65F615\u5206",
"trade_source":0,"storage_uid":"002079C1E5B437B6B730DA1EE9D2C65B",
"storage_name":"\u9ED8\u8BA4\u4ED3\u5E93",
"return_flag":0,"tp_discount":0.0,"showName":"[\u6DD8\u5B9D]BV",
"tp_cortid":"TB14631495442220979","tp_invoice":null,"tp_delivery_type":3,"tp_wlb":0,
"history":false,"tp_has_agent":0,"trade_end_time":"2014-10-21T23:35:31Z",
"tp_addition":"\u9644: \u6668\u5149\u7B7E\u5B57\u7B1420215,\u6EDA\u7B52\u6D17\u8863\u673A,
\u542B\u8D39\u752839.09\u5143","tp_flag":1,"hasChild":true,"exp_shop":null,"s":null,
"distr_uid":null,"tp_exp_agen":0.0,"pay_uid":null,"gx_post_fee":null,"goods_count":2,
"distr_pay_status":null,"distr_pay_type":null}],"pageSize":1,
"pageNo":1,"pageCount":7567,"entityCount":7567},"$dataTypeDefinitions":[],"$context":{}}'
jsonObj = JSON.parseObject(str.encode('UTF-8'))
jsonArray = jsonObj.getJSONObject("data").getJSONArray("data").
getJSONObject(0);
#结合脚本实现方式,可选择获取不同数据类型
entityCount1 = jsonObj.get("data").get("entityCount")
entityCount2 = jsonObj.get("data").getIntValue("entityCount")
entityCount3 = jsonObj.get("data").getString("entityCount")
isWrapper = jsonObj.get("data").get("$isWrapper")
bill_type = jsonArray.get( "bill_type")
custom_code = jsonArray.get( "custom_code")
3.2.3.脚本范例
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from net.grinder.script.Grinder import grinder
from net.grinder.script import Test
from util import Trunner
from com.alibaba.fastjson import JSON
from com.alibaba.fastjson import JSONObject
from com.alibaba.fastjson import JSONArray
# 导入HTTP支持模块
from net.grinder.plugin.http import HTTPPluginControl
from net.grinder.plugin.http import HTTPRequest
from HTTPClient import CookieModule
from HTTPClient import NVPair
# 导入Java标准类库中的类来使用
from java.util import Random
from com.taobao.qa.perf.tr.script import PapClient
# 获取默认HTTP连接配置对象
connectionDefaults = HTTPPluginControl.getConnectionDefaults()
# 设置HTTP客户端发送请求时,使用GBK来进行URL编码
connectionDefaults.setEncoding('GBK')
# 用户自定义HTTP请求头信息
defaultHeaders = [NVPair('Accept-Encoding', 'gzip'), \
NVPair('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'), \
NVPair('User-Agent' , 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.22 (KHTML, like Gecko) Chrome/25.0.1364.172')
]
# 测试类框架,每个测试线程辉创建一个TestRunner对象,对象成员线程安全
# __init__方法对象创建时调用一次,__call__方法在测试过程中被循环多次调用,__del__在对象销毁时执行一次
class TestRunner:
def __init__(self):
# 在__init__方法中执行登录方法,这样用户登录一次,后续可以多次执行业务操作
self.login()
# 获得登录后的HTTP Cookie信息,保存在TestRunner对象的成员变量login_cookies中
self.threadContext = HTTPPluginControl.getThreadHTTPClientContext()
self.login_cookies = CookieModule.listAllCookies(self.threadContext)
# 创建一个随机对象
self.rd = Random()
# 成员方法,用来实现用户登录
def login(self):
request = HTTPRequest()
request.setHeaders([NVPair('Content-Type', 'application/json'),])
result = request.POST('http://xxx.xxxx.xxx.xxx/login/emailLogin', '{"email":"xxx@xxxx.com","pwd":"xxx"}')
# 定义一个性能测试事务:发货单发货,先获取列表,然后遍历一一打单(填充物流单)、发货
def deliveryOrderDeliveryList(self):
total=0
page=1
rows=10
pageCount=1
statusCode = [0L, 0L, 0L, 0L]
while page<=pageCount:
request = HTTPRequest()
result = request.GET('http://xxx.xxx.xxx.xxx/tc/delivery/delivery_order_header/data/list?page='+str(page)+'&rows='+str(rows)+'&delivery=0&time='+str(Random()))
Trunner.addHttpCode(result.getStatusCode(), statusCode)
# 返回结果是json格式,包含订单总数,一页的订单信息
jsonObj = JSON.parseObject
(result.getText().encode('UTF-8'))
total= jsonObj.getIntValue('total')
rowsList= jsonObj.getIntValue('rows')
# 将返回的订单信息中的id抽取出来
ids=self._convertToStr(rowsList)
ids1=self._convertToStr1(rowsList)
# 将抽取出来的订单填充物流信息
statusCode2=self._fillLogistics(ids1)
Trunner.setExtraData(statusCode2)
# 将填充好物流信息的订单进行发货操作
statusCode1=self._deliveryOrderDelivery(ids)
Trunner.setExtraData(statusCode1)
page=page+1
# 如果没有更多订单推出循环
if(total==0):
break
# 如果有订单,计算查询到的订单页数
else:
if(total%rows<=0):
pageCount=total/rows
else:
pageCount=total/rows+1
return statusCode
# 订单进行发货操作的子函数
def _deliveryOrderDelivery(self,ids):
statusCode = [0L, 0L, 0L, 0L]
request = HTTPRequest()
request.setHeaders([NVPair('Content-Type', 'application/json'),])
result = request.POST('http://xxx.xxx.xxx.xxx/tc/delivery/delivery_order_header/delivery',ids)
Trunner.addHttpCode(result.getStatusCode(), statusCode)
return statusCode
# 订单进行物流信息填充的子函数
def _fillLogistics(self,ids):
statusCode = [0L, 0L, 0L, 0L]
request = HTTPRequest()
request.setHeaders([NVPair('Content-Type', 'application/json'),])
result = request.POST('http://xxx.xxx.xxx.xxx/tc/delivery/logistics/fillLogistics',ids)
Trunner.addHttpCode(result.getStatusCode(), statusCode)
return statusCode
# 用于将json格式的订单信息转换成id列表的子函数
def _convertToStr(self,rowsList):
tempIds='['
for x in range(len(rowsList)):
if(x==0):
tempIds=tempIds+'{"id":"'+rowsList[x]['id']+'"}'
else:
tempIds=tempIds+',{"id":"'+rowsList[x]['id']+'"}'
tempIds=tempIds+']'
return tempIds
def _convertToStr1(self,rowsList):
tempIds='['
for x in range(len(rowsList)):
if(x==0):
tempIds=tempIds+'{"id":"'+rowsList[x]['id']+'","mailNo":"'+str(Random().nextInt())+'"}'
else:
tempIds=tempIds+',{"id":"'+rowsList[x]['id']+'","mailNo":"'+str(Random().nextInt())+'"}'
tempIds=tempIds+']'
return tempIds
def __call__(self):
# 由于每次__call__循环回丢弃所有cookie信息,所以需要手动添加__init__方法中保存的登录cookie信息
for c in self.login_cookies:
CookieModule.addCookie(c, self.threadContext)
# 框架代码,延迟性能数据汇报,等待所有事务运行结束再汇报
grinder.statistics.delayReports = 1
# 调用查询订单并进行填充发货的事务
statusCode=self.deliveryOrderDeliveryList()
Trunner.setExtraData(statusCode)
# 框架代码,强制汇报性能数据
grinder.statistics.report()
grinder.statistics.delayReports = 0
# Instrument性能测试事务,参数为:事务所在脚本ID,事务名称,事务描述,事务对应的方法名称,TestRunner类
Trunner.instrumentMethod(Test(PapClient.getId(1415, 'deliveryOrderDeliveryList'), 'deliveryOrderDeliveryList'), 'deliveryOrderDeliveryList', TestRunner)
Trunner.instrumentMethod(Test(PapClient.getId(1415, '_deliveryOrderDelivery'), '_deliveryOrderDelivery'), '_deliveryOrderDelivery', TestRunner)
Trunner.instrumentMethod(Test(PapClient.getId(1415, '_fillLogistics'), '_fillLogistics'), '_fillLogistics', TestRunner)
3.3.4.域名绑定
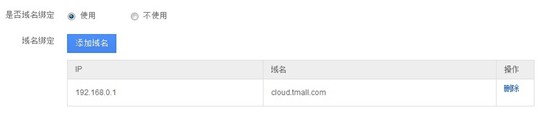
如果待测系统通过域名进行访问,可在此进行域名绑定,一个IP地址可绑定多个域名。如果域名为线上正式在使用中,请务必绑定测试IP,否则默认是试压线上机器而被阻止,导致任务失败。
注意:IP地址只能输入服务开通时分配到的ECS服务器IP,输入其他IP在压测时不会生效。
3.3.5.参数化
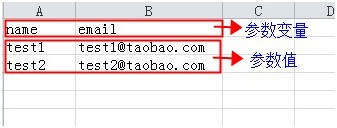
如果想让测试数据更丰富可对脚本进行参数化。参数化步骤如下:
- 上传参数文件,目前仅支持csv格式,可在此下载模板。参数文件第一行为参数变量,可增加多个参数变量;从第二行开始为参数值,可增加多个参数值,脚本运行时会读取对应参数变量的参数值按从上往下的顺序执行。可上传多个参数文件,上传完毕后参数文件默认为启用。

- 在请求链接中选中要进行参数化的参数值,然后点击参数化按钮进行参数化。
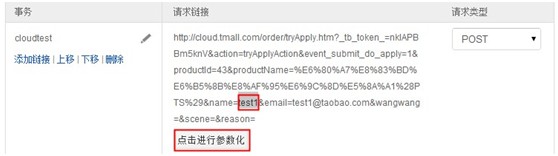
- 在参数化窗口选择参数文件及参数变量,参数变量可通过系统自动读取参数文件获得也可手工输入。
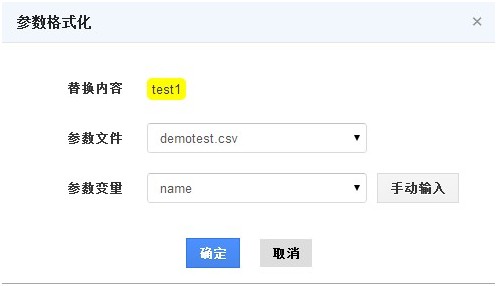
- 系统自动完成替换,替换格式为“%%_参数文件名:参数变量%%”。

- 一个参数文件或参数变量可用于多个不同链接里,一个链接也可对应多个不同的参数文件或参数变量。
3.4.性能场景

- 常规模式:一次性加载所有用户。
- 迭代模式:分批增加或减少用户。递增用于控制任务启动时用户增加的频率,递减用于任务停止时用户减少的频率。
- 目标模式:达到指定目标阈值后停止压测。例如下图配置运行时的效果是:事务“cloudtest”的响应时间达到100ms或服务器CPU占用率达到80%后停止压测。

- 一个场景只能对应一个脚本。
- PTS标准版的并发用户数上限为100,如有特殊压测需求请联系技术支持。
3.5.性能任务
3.5.1.新建任务

持续时间最短不能少于10分钟。
一个任务可添加多个场景。
点击启动之后,需要短暂的启动时间,任务表状态显示'启动中'

3.5.2.任务操作
执行:启动任务。
停止:停止任务。
添加并发用户:任务启动后实时增加并发用户数。
实时监控:实时监控性能指标。
删除:只能删除未启动的任务。
刷新:刷新任务列表,查看任务最新状态。
3.6.结果查看
3.6.1.日志查看
如果任务执行之后,状态显示‘失败’,可通过点击状态查看日志信息

日志分析方法:
1. 点击任务状态栏的状态,比如上面的”失败”状态,打开日志页面.
2. 日志页面的主要功能如下:

3. 通过任务信息,来确认任务是否自己所执行的任务。
4. 通过场景运行信息,来确认自己的场景在哪台机器上执行。【施压机】
5. 任务运行过程日志显示了任务执行过程中所经过的模块和结果信息,通过这个信息可以。初步判断任务是在哪个阶段失败了。
6. 接下来最主要的 就是【节点日志】和【压测进程日志】这两部分内容。
7. 节点日志主要记录了压测节点【施压机】在接收到任务以后,运行启动过程中所出现的日志,它主要包括【程序日志】、【消息日志】和【初始化日志】。
【程序日志】:记录压测进程在接收到任务以后,初始化、启动的结果信息。

分析:该日志对用户一般没有参考意义,只有在部署压测节点时,通过日志判断节点是否启动成功,跟任务的执行一般没有关系。
【消息日志】:记录压测节点进程在整个消息的处理过程和结果,主要包括平台与压测节点的消息通讯和压测机点之间的消息通讯。

分析:该日志对用户的参考意义也不大,可以通过该日志判断哪一步消息处理出错,但为什么出错还要进一步分析。消息的正确过程一般是,任务注册成功->修改任务状态[REGISTERED]->任务初始化成功-> 修改任务状态[INITIALIZED]->测试任务开始运行->修改任务状态[RUNNING]->测试进程结束、任务注销成功
【初始化日志】:记录压测节点在接收任务以后,开始初始化的过程和结果。初始化一般包括消息初始化、初始化脚本、初始化参数文件等。

分析:该日志一般是在系统打包失败或者脚本初始化失败的时候,用来判断什么原因,比如下载脚本失败,打包上传失败等等
8. 压测进程日志就是节点进程在启动压测进程后,压测进程运行任务所输出的日志,该日志是判断任务启动失败原因的重要参考数据。
【out日志】: 测试进程通过标准系统输出的日志,比如print语法输出的内容。
分析:该日志一般用来展示用户自定义输出的内容,通过该内容判断用户在运行脚本时获取的数据是否正确。
比如用户访问一个页面:result = HTTPRequest().GET('http://www.baidu.com'),用户可以通过print(result.getText())将访问该页面后的response响应内容全部在日志中输出,而这个print输出的日志,会输出到out日志当中,用户可以点击后查看。
【log日志】:测试进程通过日志系统输出的日志,比如:http脚本存,request请求信息等,该日志一般记录了和测试进程有关的所有信息。

分析:该日志一般是用来判断用户在请求url的过程中是否正确,HTTP状态码常见的分为1**,2**,3**,4**,5**等
1**代表消息,比如100 Continue 101 Switching Protocols等。
2**代表请求已成功被服务器接收、理解、并接受,比如 200 OK 201 Created 202 Accepted
3**代表重定向,比如 300 Multiple Choices 301 Moved Permanently 302 Found 304 Not Modified
4**代表请求错误,比如 400 Bad Request 401 Unauthorized 402 Payment Required 403 Forbidden 404 Not Found
5**代表服务器错误,比如500 Internal Server Error 501 Not Implemented 502 Bad Gateway 503 Service Unavailable
而图中显示请求全部为302跳转,可能是未登录,也可能其他原因,需要排查。
另外,一般日志级别都是ERROR(可改,联系管理员),所以log日志中显示的都是非200状态码的请求信息,200状态码返回是不显示的
【Error日志】:测试进程通过错误系统输出的日志,比如:system.err 和exception 的异常
事务的失败不是异常,所以不会再error当中显示,只有在系统启动失败的时候,才会在在error日志中有异常信息。所以如果启动成功但事务失败,应该看log日志文件内容。
此外,脚本编辑页面中的手工脚本编写中提供了【调试】功能,调试执行后,同样会有3个日志,包括out、error和log日志,作用同上面介绍的相同,所以如果是手工编写(模板编写脚本可以忽略),建议大家在执行任务前先进行脚本的调试,观察日志和请求过程是否有问题,再来真正的启动任务 ,启动压测。
3.6.2.指标查看
任务执行完之后,可以通过两个入口查看服务器和业务指标结果:

【业务指标】
业务指标主要监控的是TPS、响应时间、并发用户数、请求状态

【ECS指标】
测试服务器ECS主要监控的是cpu、网络带宽、磁盘空间
【RDS指标】
测试数据库RDS主要监控的是cpu、连接数、IOPS、TPS、磁盘空间、QPS

