相对于传统应用程序,开发云端应用虽然降低了用户在基础设施搭建、运维等方面的成本,但却增大了监控、诊断和故障排查的难度。OSS存储服务为您提供了丰富的监控和日志信息,帮助您深刻洞察程序行为,及时发现并快速定位问题。
- 实时监控OSS存储服务的运行状况和性能,并及时报警通知。
- 获取有效的方法和工具来定位问题。
- 根据相关问题的处理和操作指南,快速解决与OSS相关的问题。
服务监控
- 监视总体运行状况
- 可用性和有效请求率
可用性和有效请求率是有关系统稳定性和用户是否正确使用系统的最重要指标,指标小于100%说明某些请求失败。

可能因为一些系统优化因素出现暂时性的低于100%,例如为了负载均衡而出现分区迁移,此时OSS的SDK能够提供相关的重试机制无缝处理这类间歇性的失败情况,使得业务端无感知。
对于有效请求率低于100%的情况,您需要根据自己的使用情况进行分析,可以通过请求分布统计或者请求状态详情确定错误请求的具体类型、原因,并排除故障。
对于某些业务场景,出现有效请求率低于100%是符合预期的。例如,用户需要先检查访问的Object是否存在,然后根据Object的存在性采取一定的操作,如果Object不存在,检测Object存在性的读取请求会收到404错误(资源不存在错误),导致该指标项低于100%。
对于系统可用性指标要求较高的业务,可以对其设置报警规则,当低于预期阈值时,进行报警。
- 总请求数和有效请求数
该指标从总访问量角度来反应系统运行状态,当有效请求数不等于总请求数时表明某些请求失败。
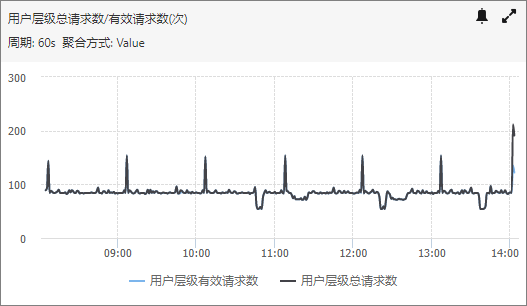
您可以关注总请求数或者有效请求数的波动状况,特别是突然上升或者下降的情况,需要进行跟进调查,可以通过设置报警规则进行及时通知,对于存在周期性状况的业务,可以设置为环比报警规则(环比报警方式即将上线),详见报警服务使用指南。
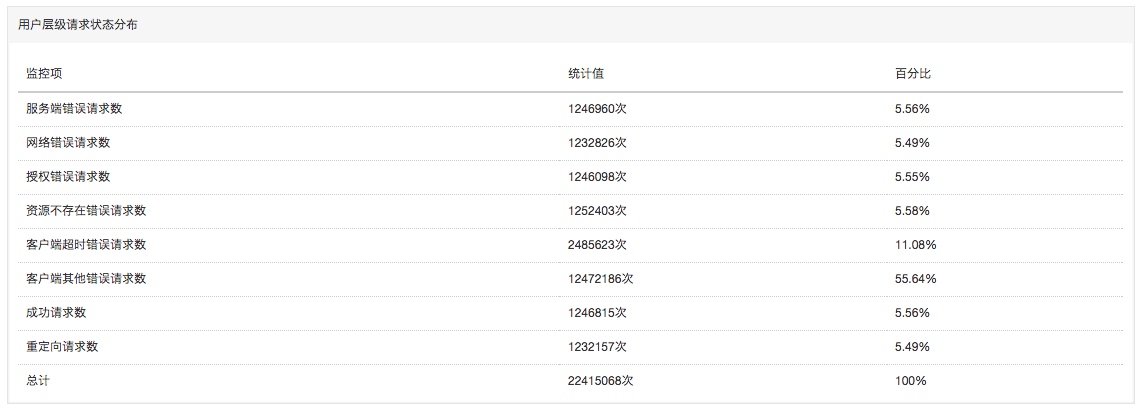
- 请求状态分布统计
当可用性或者有效请求率低于100%(或者有效请求数不等于总请求数时),可以通过查看请求状态分布统计快速确定请求的错误类型,该统计监控指标的详细介绍参见OSS监控指标参考手册。
- 可用性和有效请求率
- 监视请求状态详情
请求状态详情是在请求状态分布统计的基础上进一步细化请求监控状态,可以更加深入、具体地监视某类请求。

- 监视性能
监控服务提供了以下监控项来监控性能相关的指标:
- 平均延时,包括E2E平均延时和服务器平均延时
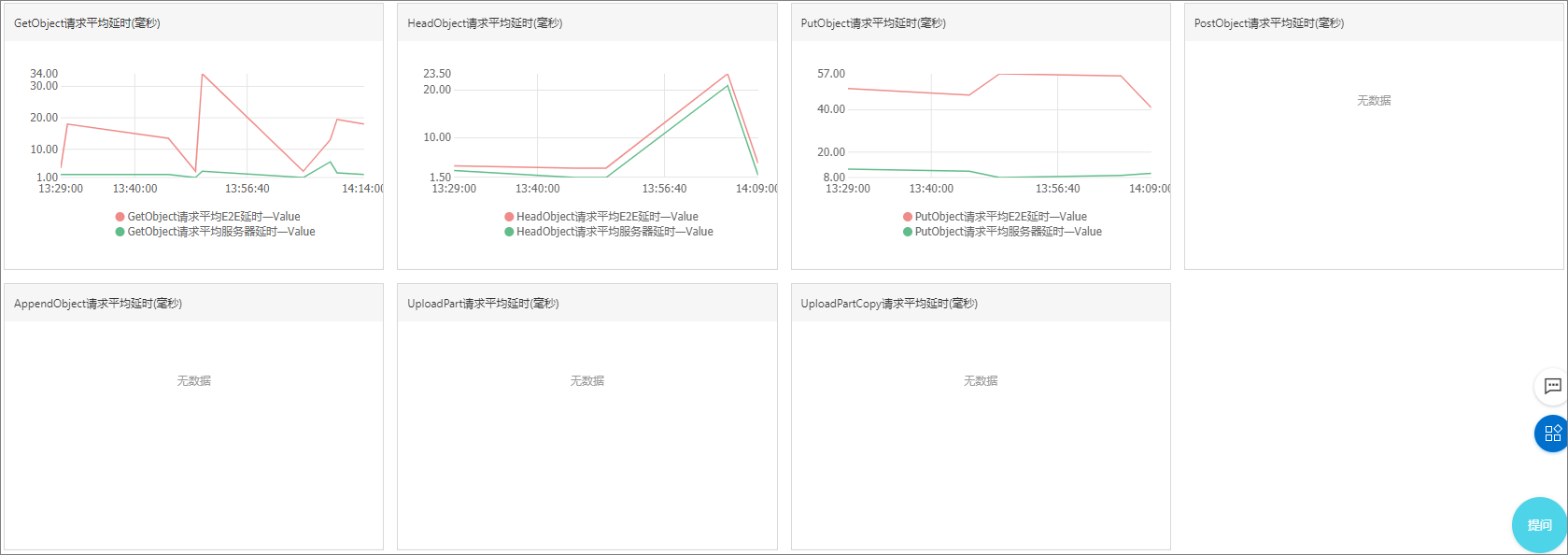
延时指标显示API操作类型处理请求所需的平均和最大时间。其中E2E延时是端到端延迟指标,除了包括处理请求所需的时间外,还包括读取请求和发送响应所需的时间以及请求在网络上传输的延时;而服务器延时只是请求在服务器端被处理的时间,不包括与客户端通信的网络延时。所以当出现E2E延时突然升高的情况下,如果服务器延时并没有很大的变化,那么可以判定是网络的不稳定因素造成的性能问题,排除OSS系统内部故障。
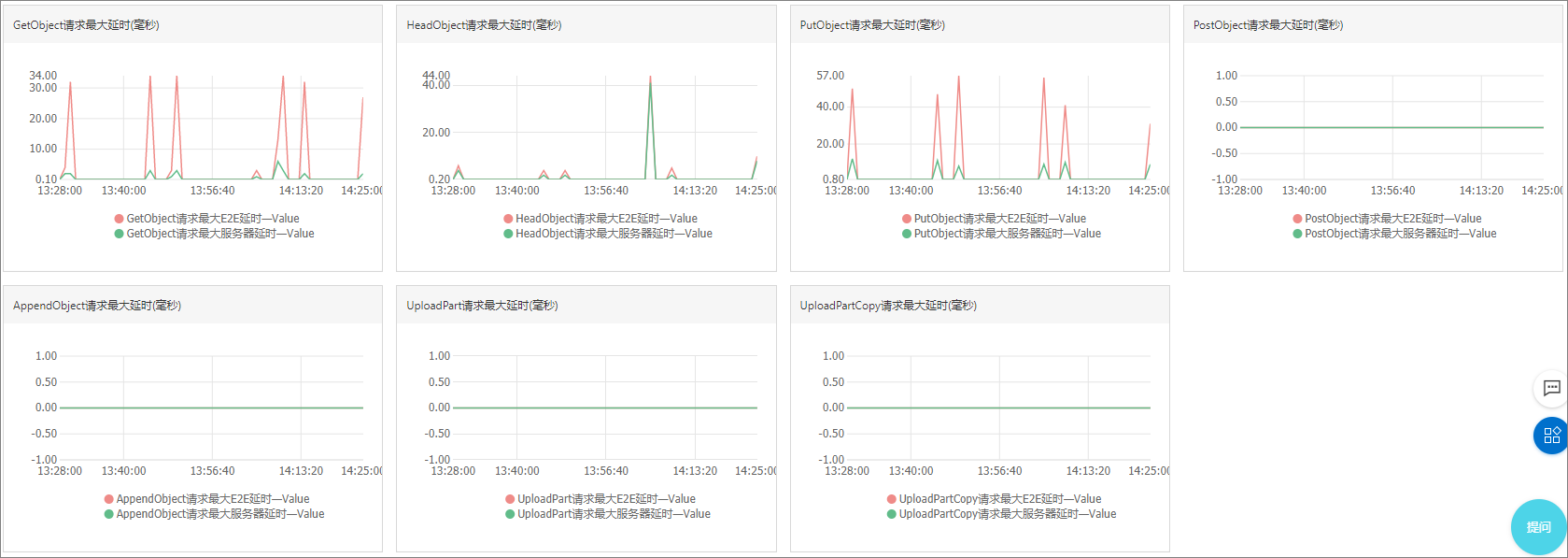
- 最大延时,包括E2E最大延时和服务器最大延时
- 成功请求操作分类
- 流量
流量指标从用户或者具体的Bucket层级的总体情况进行监控,关注公网、内网、CDN回源以及跨域复制等场景中的网络资源占用状况。
以上各个监控项(除流量)都分别从API操作类型进行分类监控,包括:- GetObject
- HeadObject
- PutObject
- PostObject
- AppendObject
- UploadPart
- UploadPartCopy
成功请求操作分类除了以上提到的API之外,还提供以下两个API操作类型请求数量的监控:- DeleteObject
- DeleteObjects
对于性能类指标项,您需要重点关注其突发的异常变化。例如,平均延时突然出现尖峰,或者长时间处于高出正常请求延时的基线上方等。您可以通过对性能指标设置对应的报警规则,当指标低于或者超过阈值时及时通知到相关人员。
- 平均延时,包括E2E平均延时和服务器平均延时
- 监视计量
目前,OSS监控服务只支持监控存储空间大小、公网流出流量、Put类请求数和Get类请求数(不包括跨区域复制流出流量和CDN流出流量),不支持对计量数据的报警设置和OpenAPI的读取。
OSS监控服务对Bucket层级的计量监控数据进行小时级别的粒度采集,可以在具体的Bucket监控视图中查看其持续的监控趋势图。您可以根据监控视图分析其业务的存储服务资源使用趋势并且进行成本的预估等。
OSS监控服务还提供了用户层级和Bucket层级两个不同维度的当月消费的资源数统计。即统计阿里云账户或者某个Bucket当月消耗的OSS资源总量,每小时更新一次,帮助您了解本月资源的使用情况并计算消费。
OSS的计费项和计算方式请参见 计量项和计费项。说明 监控服务中提供的计量数据是尽最大可能推送的,可能会与实际消费账单不一致,请以费用中心的数据为准。
跟踪诊断
- 问题诊断
- 诊断性能
对于应用程序的性能判断多带有主观因素,您需要根据具体的业务场景确定满足业务需求的基准线,来判定性能问题。另外,从客户端发起的请求,能引起性能问题的因素贯穿整个请求链路。例如OSS存储服务负载过大、客户端TCP配置问题或网络基础结构中存在的流量瓶颈等。
因此诊断性能问题首先需要设置合理的基准线,然后通过监控服务提供的性能指标确定性能问题可能的根源位置,然后根据日志查到详细的信息以便进一步诊断并且排除故障。
在下文故障排除中例举了常见的性能问题和排查措施,可以参考。
- 诊断错误
客户端应用程序会在请求发生错误时接收到服务端返回的相关错误信息,监控服务也会记录并显示各种错误类型请求的计数和占比。您也可以通过检查服务器端日志、客户端日志和网络日志来获取相关单个请求的详细信息。通常,响应中返回的HTTP状态代码和OSS错误码以及OSS错误信息都指示请求失败的原因。
相关错误响应信息请参见 OSS错误响应。
- 使用日志功能
OSS存储服务为用户的请求提供服务端日志记录功能,能帮助用户记录端到端的详细请求日志跟踪。
有关如何开启并使用日志功能,请参见设置日志。
有关日志服务的命名规则以及记录格式等详细信息,请参见设置访问日志记录。
- 使用网络日志记录工具
在大多数情况下,通过日志服务记录的存储日志和客户端应用程序的日志数据已足以诊断问题,但在某些情况下,可能需要更详细的信息,这时需要使用网络日志记录工具捕获客户端和服务器之间的流量,可以更详细地获取客户端和服务器之间交换的数据以及底层网络状况的详细信息,帮助问题的调查。例如,在某些情况下,用户请求可能会报告一个错误,而服务器端日志中却看不到任何该请求的访问情况,这时就可以使用OSS的日志服务功能记录的日志来调查该问题的原因是否出在客户端上,或者使用网络监视工具来调查网络问题。
最常用的网络日志分析工具之一是Wireshark。该免费的协议分析器运行在数据包级别,能够查看各种网络协议的详细数据包信息,从而可以排查丢失的数据包和连接问题。
WireShark使用参见WireShark安装使用。
更详细的WireShark操作请参见WireShark用户指南。
- 诊断性能
- E2E跟踪诊断
请求从客户端应用进程发起,通过网络环境,进入OSS服务端被处理,然后响应从服务端回到网络环境,被客户端接收。整个过程,是一个端到端的跟踪过程。关联客户端应用程序日志、网络跟踪日志和服务端日志,有助于排查问题的详细信息根源,发现潜在的问题。
在OSS存储服务中,提供了RequestID作为关联各处日志信息的标识符。另外,通过日志的时间戳,不仅可以迅速查找和定位日志范围,还能够了解在请求发生时间点范围内,客户端应用、网络或者服务系统发生的其他事件,有利于问题的分析和调查。- RequestID
OSS服务会为接收的每个请求分配唯一的服务器请求ID,即RequestID。在不同的日志中,RequestID位于不同的字段中:
- 在OSS日志功能记录的服务端日志记录中,RequestID出现在“Request ID”列中。
- 在网络跟踪(如WireShark捕获的数据流)中,RequestID作为x-oss-request-id标头值出现在响应消息中。
- 在客户端应用中,需要客户端code实现的时候将请求的RequestID自行打印到客户端日志中。最新版本的Java SDK已经支持打印正常请求的RequestID信息,可以通过各个API接口返回的Result结果的getRequestId这个方法获取。OSS的各个版本SDK都支持打印出异常请求的RequestID,可以通过调用OSSException的getRequestId方法获取。
- 时间戳
使用时间戳来查找相关日志项,需要注意客户端和服务器之间可能存在的时间偏差。在客户端上基于时间戳搜索日志功能记录的服务器端日志条目时,应加或减15分钟。
- RequestID
故障排除
- 性能相关常见问题
- 平均E2E延时高,而平均服务端延时低
前面介绍了平均E2E延时与平均服务器延时的区别。所以产生高E2E延时、低服务器延时可能的原因有两个:
- 客户端应用程序响应慢
- 可用连接数或可用线程数有限
- 对于可用连接数问题,可以使用相关命令确定系统是否存在大量TIME_WAIT状态的连接。如果是,可以通过调整内核参数解决。
- 对于可用线程数有限,可以先查看客户端CPU、内存、网络等资源是否已经存在瓶颈,如果没有,适当调大并发线程数。
- 如果还不能解决问题,那么就需要通过优化客户端代码。例如,使用异步访问方式等。也可以使用性能分析功能分析客户端应用程序热点,然后具体优化。
- CPU、内存或网络带宽等资源不足
对于这类问题,需要先使用相关系统的资源监控查看客户端具体的资源瓶颈在哪里,然后通过优化代码使其对资源的使用更为合理,或者扩容客户端资源(使用更多的内核或者内存)。
- 可用连接数或可用线程数有限
- 网络原因导致
通常,因网络导致的端到端高延迟是由暂时状况导致的。可以使用Wireshark调查临时和持久网络问题,例如数据包丢失问题。
- 客户端应用程序响应慢
- 平均E2E延时低,平均服务端延时低,但客户端请求延时高
客户端出现请求延时高的情况,最可能的原因是请求还未达到服务端就出现了延时。所以应该调查来自客户端的请求为什么未到达服务器。
对于客户端延迟发送请求,可能的客户端的原因有两个:
- 可用连接数或可用线程数有限
- 对于可用连接数问题,可以使用相关命令确定系统是否存在大量TIME_WAIT状态的连接。如果是,可以通过调整内核参数解决。
- 对于可用线程数有限,可以先查看客户端CPU、内存、网络等资源是否已经存在瓶颈,如果没有,适当调大并发线程数。
- 如果还不能解决问题,那么就需要通过优化客户端代码。例如,使用异步访问方式等。也可以使用性能分析功能分析客户端应用程序热点,然后具体优化。
- 客户端请求出现多次重试,如果遇到这种情况,需要根据重试信息具体调查重试的原因再解决。可以通过下面方式确定客户端是否出现重试:
- 检查客户端日志,详细日志记录会指示重试已发生过。以OSS的Java SDK为例,可以搜索如下日志提示,warn或者info的级别。如果存在该日志,说明可能出现了重试。
[Server]Unable to execute HTTP request: 或者 [Client]Unable to execute HTTP request:
- 如果客户端的日志级别为debug,以OSS的Java SDK为例,可以搜索如下日志,如果存在,那么肯定出现过重试。
Retrying on
- 检查客户端日志,详细日志记录会指示重试已发生过。以OSS的Java SDK为例,可以搜索如下日志提示,warn或者info的级别。如果存在该日志,说明可能出现了重试。
如果客户端没有问题,则应调查潜在的网络问题,例如数据包丢失。可以使用工具(如Wireshark )调查网络问题。
WireShark使用参见WireShark安装使用。
- 可用连接数或可用线程数有限
- 平均服务端延时高
对于下载或者上传出现服务端高延时的情况,可能的原因有2个:
- 大量客户端频繁访问同一个小Object
这种情况,可以通过查看日志功能记录的服务端日志信息来确定是否在一段时间内,某个或某组Object被频繁访问。
对于下载场景,建议用户为该Bucket开通CDN服务,利用CDN来提升性能,并且可以节约流量费用;对于上传场景,用户可以考虑在不影响业务需求的情况下,收回Object或Bucket的写访问权限。
- 系统内部因素
对于系统内部问题或者不能通过优化方式解决的问题,请提供客户端日志或者日志功能记录的日志信息中的RequestID,联系售后技术人员协助解决。
- 大量客户端频繁访问同一个小Object
- 平均E2E延时高,而平均服务端延时低
- 服务端错误问题
对于服务端错误的增加,可以分为两个场景考虑:
- 暂时性的增加
对于这一类问题,您需要调整客户端程序中的重试策略,采用合理的退让机制,例如指数退避。这样不仅可以有效避免因为优化或者升级等系统操作(如为了系统负载均衡进行分区迁移等)暂时导致的服务不可用问题,还可以避开业务峰值的压力。
- 永久性的增加
如果服务端错误持续在一个较高的水平,那么请提供客户端日志或者日志功能记录的RequestID,联系售后技术人员协助调查。
- 暂时性的增加
- 网络错误问题
网络错误是指服务端正在处理请求时,连接在非服务器端断开而来不及返回HTTP请求头的情况。此时系统会记录该请求的HTTP状态码为499。以下几种情况会导致服务器记录请求的状态码变为499:
- 服务器在收到读写请求处理之前,会检查连接是否可用,不可用则为499。
- 服务器正在处理请求时,客户端提前关闭了连接,此时请求被记录为499。
在请求过程中,客户端主动关闭请求或者客户端网络断掉都会产生网络错误。对于客户端主动关闭请求的情况,需要调查客户端中的代码,了解客户端断开与存储服务连接的原因和时间。对于客户端网络断掉的情况,用户可以使用工具(如Wireshark)调查网络连接问题。
WireShark使用参见WireShark安装使用。
- 客户端错误问题
- 客户端授权错误请求增加
当监控中的客户端授权错误请求数增加,或者客户端程序接收到大量的403请求错误,那么最常见的可能原因有以下几个:
- 用户访问的Bucket域名不正确
- 如果用户直接用三级域名或者二级域名访问,那么可能的原因就是用户的Bucket并不属于该域名所指示的region内,例如,用户创建的Bucket的地域为杭州,但是访问的域名却为Bucket.oss-cn-shanghai.aliyuncs.com。这时需要确认Bucket的所属区域,然后更正域名信息。
- 如果用户开启了CDN加速服务,那么可能的原因是CDN绑定的回源域名错了,请检查CDN回源域名是否为用户Bucket的三级域名。
- 如果用户使用javascript客户端遇到403错误,可能的原因就是CORS(跨域资源共享)的设置问题,因为Web浏览器实施了“同源策略”的安全限制。用户需要先检查所属Bucket的CORS设置是否正确,并进行相应的更正。设置CORS参见跨域资源共享。
- 访问控制问题
- 用户使用主AK访问,那么用户需要检查是否AK设置出错,使用了无效AK。
- 用户使用RAM子账号访问,那么用户需要确定RAM子账号是否使用了正确的子AK,或者对应子账号的相关操作是否已经授权。
- 用户使用STS临时Token访问,那么用户需要确认一下这个临时Token是否已经过期。如果过期,需要重新申请。
- 如果Bucket或者Object设置了访问控制,这个时候需要查看用户所访问的Bucket或者Object是否支持相关的操作。
- URL过期
授权第三方下载,即用户使用签名URL进行OSS资源访问,如果之前访问正常而突然遇到403错误,最大可能的原因是URL已经过期。
- RAM子账号使用OSS周边工具的情况也会出现403错误。这类周边工具如ossftp、ossbrowser、OSS控制台客户端等,在填写相关的AK信息登入时就抛出错误,此时如果您的AK是正确填写的,那么您需要查看使用的AK是否为子账号AK,该子账号是否有GetService等操作的授权等。
- 用户访问的Bucket域名不正确
- 客户端资源不存在错误请求增加
客户端收到404错误说明用户试图访问不存在的资源信息。当看到监控服务上资源不存在错误请求增加,那么最大可能是以下问题导致的:
- 用户的业务使用方式。例如用户需要先检查Object是否存在来进行下一步动作,可以调用doesObjectExist(以JAVA SDK为例)方法,如果Object不存在,在客户端则收到false值,但是这时在服务器端实际上会产生一个404的请求信息。所以,这种业务场景下,出现404是正常的业务行为。
- 客户端或其他进程以前删除了该对象。这种情况可以通过搜索logging功能记录的服务端日志信息中的相关对象操作即可确认。
- 网络故障引起丢包重试。例如客户端发起一个删除操作删除某个Object,此时请求达到服务端,执行删除成功,但是响应在网络环境中丢包,然后客户端发起重试,第二次的删除操作可能就会遇到404错误。这种由于网络问题引起的404错误可以通过客户端日志和服务端日志确定:
- 查看客户端应用日志是否出现重试请求。
- 查看服务端日志是否对该Object有两次删除操作,前一次的删除操作HTTP Status为2xx。
- 有效请求率低且客户端其他错误请求数高
有效请求率为请求返回的HTTP状态码为2xx/3xx的请求数占总请求的比例。状态码为4XX和5XX范围内的请求将计为失败并降低该比例。客户端其他错误请求是指除服务端错误请求(5xx)、网络错误请求(499)、客户端授权错误请求(403)、客户端资源不存在错误请求(404)和客户端超时错误请求(408或者OSS错误码为RequestTimeout的400请求)这些错误请求之外的请求。
您可以通过查看日志功能记录的服务端日志确定这些错误的具体类型,之后根据OSS错误响应码在客户端代码中查找具体原因进行解决。详情请参见OSS错误响应。
- 客户端授权错误请求增加
- 存储容量异常增加
存储容量异常增加,如果不是上传类请求量增多,常见的原因应该是清理操作出现了问题,可以根据下面两个方面进行调查:
- 客户端应用使用特定的进程定期清理来释放空间。针对这种请求的调查步骤是:
- 查看有效请求率指标是否下降,因为失败的删除请求会导致清理操作没能按预期完成。
- 定位请求有效率降低的具体原因,查看具体是什么错误类型的请求导致。然后还可以结合具体的客户端日志定位更详细的错误信息(例如,用于释放空间的STS临时Token已过期)。
- 客户端通过设置LifeCycle来清理空间:针对这种请求,需要通过控制台或者API接口查看目前Bucket的LifeCycle是否为之前设置的预期值。如果不是,可以直接更正目前配置;进一步的调查可以通过Logging功能记录的服务端日志记录查询以前修改的具体信息。如果LifeCycle是正常的,但是却没有生效,请联系OSS系统管理员协助调查。
- 客户端应用使用特定的进程定期清理来释放空间。针对这种请求的调查步骤是:
- 其他存储服务问题
如果前面的故障排除章节未包括您遇到的存储服务问题,则可以采用以下方法来诊断和排查您的问题:
- 查看OSS监控服务,了解与预期的基准行为相比是否存在任何更改。监控视图可能能够确定此问题是暂时的还是永久性的,并可确定此问题影响哪些存储操作。
- 使用监控信息来帮助您搜索日志功能记录的服务端日志数据,获取相关时间点发生的任何错误信息。此信息可能会帮助您排查和解决该问题。
- 如果服务器端日志中的信息不足以成功排查此问题,则可以使用客户端日志来调查客户端应用程序,或者配合使用网络工具(Wireshark等)调查您的网络问题。
