为保障实例的稳定和数据一致性,在使用全球分布式缓存功能时,有一些使用约束需要您注意。
子实例新购限制
- 新增的子实例不能与分布式实例中已有的子实例属于同一可用区。
- 子实例为性能增强型(本地盘版)。
- 新增的子实例的规格必须与分布式实例中已有的子实例的规格一致。
警告 如果各子实例的规格不一致,可能导致性能或容量问题。
- 一个分布式实例中最多可包含三个子实例。
子实例操作限制
- 不支持变更分布式实例中子实例的架构,例如将子实例从集群架构变更为标准架构。
- 变更规格时,要求分布式实例中的所有子实例的规格需保持一致,否则可能导致性能或容量问题。
注意 当子实例为 读写分离架构时,暂不支持变更配置。
- 升级配置时,仅支持变配至分片数翻倍的规格。例如从8分片可以变配至16分片,不能直接变配至32分片。
- 子实例不支持更换实例所属的可用区操作。
同步命令限制
- FLUSHDB或FLUSHALL命令不会被同步。如需清空数据,需对所有子实例执行FLUSHDB或FLUSHALL命令,否则会造成数据不一致。
- Pub和Sub命令族不会被同步,如需实现跨域通知的消息复制,建议通过Stream数据结构来实现。
- 同步RESTORE命令时,如果目标子实例具备相同的Key,则不会被执行。
同步粒度限制
目前同步的粒度为实例级,即子实例的所有数据都会被同步,暂不支持同步子实例中的部分数据。
说明 如需同步部分数据,需要通过业务逻辑来实现。
数据一致性限制
- 单写场景下(例如用作灾备场景),数据的一致性级别为最终数据一致。
- 多写场景下(例如用作多活场景),业务上应避免多个子实例在同一时刻或相近的时间修改同一个Key,否则可能造成数据不一致(即无法保障Key的最终一致性)或者数据堆积(在Streaming场景下严格递增产生的冲突),如下表所示。
说明 全球分布式缓存暂不支持CRDT(Conflict-Free Replicated Data Type)约束,您需要从业务层面自行保障。
不一致情况 图示 说明 value互换 
- 子实例A在1.1时刻收到SET命令(key->value_A),并于1.2时刻将数据写入数据库。
- 子实例B在2.1时刻收到SET命令(key->value_B),并于2.2时刻将数据写入数据库。
- 在3.1时刻子实例A向子实例B同步数据(key->value_A),同时子实例B向子实例A同步数据(key->value_B)。
- 同步完成,两个子实例中key对应的value发生了互换。
乱序或丢失 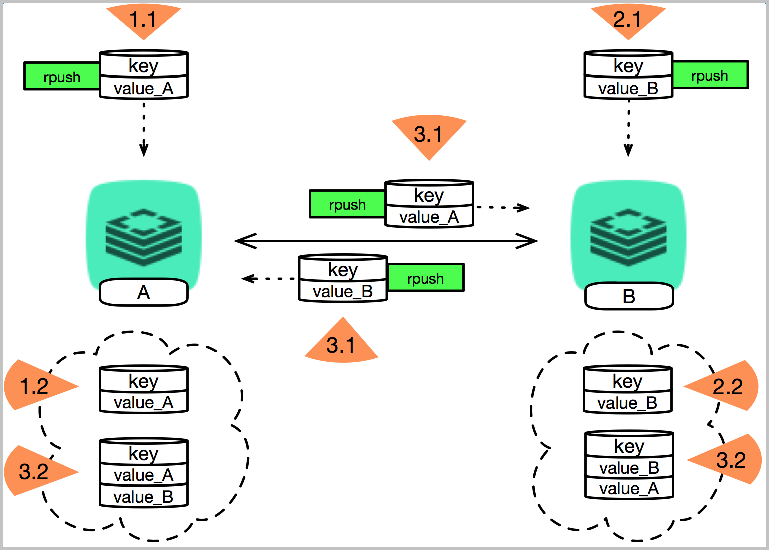
- 子实例A在1.1时刻收到命令(rpush key->value_A),并于1.2时刻将数据写入至数据库。
- 子实例B在2.1时刻收到命令(rpush key->value_B),并于2.2时刻将数据写入至数据库。
- 在3.1时刻子实例A向子实例B同步数据(rpush key->value_A),同时子实例B向子实例A同步数据(rpush key->value_B)。
- 当操作类型依赖value原始值时,在交换的情况下可能会出现乱序甚至丢失的情况。
说明 可能造成类似问题的还有、
lpush,lpop、append、sort(store)、del、hdel、incr、xadd系列等操作。
类型不一致 
- 子实例A在1.1时刻收到命令(key->T(hash)),并于1.2时刻将数据写入至数据库。
- 子实例B在2.1时刻收到命令(key->T(string)),并于2.2时刻将数据写入至数据库。
- 在3时刻子实例间执行数据同步将形成冲突。
写入条件不满足 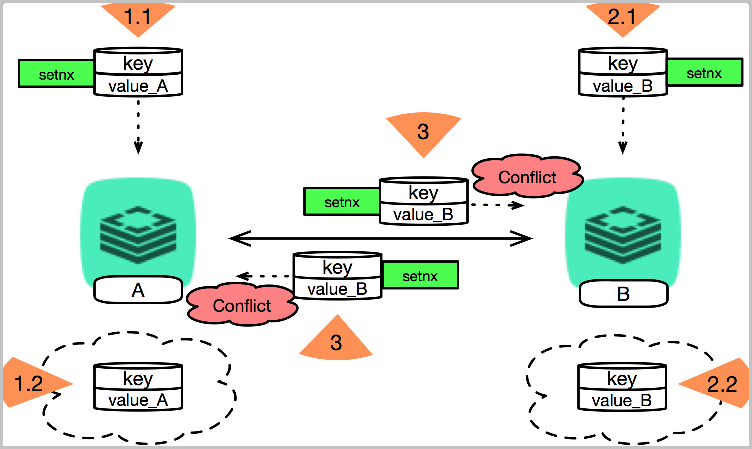
- 子实例A在1.1时刻收到命令(setnx key->value_A),并于1.2时刻将数据写入至数据库。
- 子实例B在2.1时刻收到命令(setnx key->value_B),并于2.2时刻将数据写入至数据库。
- 在3时刻子实例间执行数据同步将形成冲突。
说明 可能造成类似问题的还有
set(nx | xx)、hsetnx操作。
