您可以使用阿里云自研的imonitor命令监控Redis集群中某一节点的请求状态,并利用请求解析工具redis-faina快速地从监控数据中分析出热点Key和命令。
背景信息
在使用云数据库Redis集群版的过程中,如果某一节点上的热点Key流量过大,可能导致服务器中其它服务无法进行。若热点Key的缓存超过当前的缓存容量,就会产生缓存分片服务负载过高,进而造成缓存雪崩等严重问题。
您可以利用云数据库Redis版的性能监控和报警规则对集群状况进行实时监控并设置告警,在发现特定子节点负载突出时,使用imonitor命令查看该节点的客户端请求,并使用redis-faina分析出热点Key。
前提条件
- 已部署与云数据库Redis集群版互通的ECS实例。
- ECS实例中已安装Python和Telnet。
说明 本文中的示例环境使用CentOS 7.4系统和Python 2.7.5。
操作步骤
- 在ECS实例中,以Telnet方式连接到Redis集群。
- 使用
# telnet <host> <port>连接到Redis集群。说明host为Redis集群的连接地址,port为连接端口(默认为6379)。 - 输入
auth <password>进行认证。说明password为Redis集群的密码。
 说明 返回
说明 返回+OK表示连接成功。 - 使用
- 使用
imonitor <db_idx>收集目的节点的请求数据。 说明
说明imonitor命令与info、 iscan类似,在 monitor命令的基础上新增了一个参数,用户指定monitor执行的节点(db_idx),db_idx的范围是[0, nodecount), nodecount可以通过info命令获取,或者从控制台上的实例拓扑图中查看。
本例中目的节点的db_idx为0。
返回
+OK后将会持续输出监控到的请求记录。 - 根据需要收集一定数量的监控数据,之后输入QUIT命令并按Enter关闭Telnet连接。
- 将监控数据保存到一个.txt文件中,删除行首的 “+”(可在文本编辑工具中使用全部替换的方式)删除。保存的文件如下。

- 创建进行请求分析的Python脚本,保存为redis-faina.py。代码如下。
#! /usr/bin/env python import argparse import sys from collections import defaultdict import re line_re_24 = re.compile(r""" ^(?P<timestamp>[\d\.]+)\s(\(db\s(?P<db>\d+)\)\s)?"(?P<command>\w+)"(\s"(?P<key>[^(?<!\\)"]+)(?<!\\)")?(\s(?P<args>.+))?$ """, re.VERBOSE) line_re_26 = re.compile(r""" ^(?P<timestamp>[\d\.]+)\s\[(?P<db>\d+)\s\d+\.\d+\.\d+\.\d+:\d+]\s"(?P<command>\w+)"(\s"(?P<key>[^(?<!\\)"]+)(?<!\\)")?(\s(?P<args>.+))?$ """, re.VERBOSE) class StatCounter(object): def __init__(self, prefix_delim=':', redis_version=2.6): self.line_count = 0 self.skipped_lines = 0 self.commands = defaultdict(int) self.keys = defaultdict(int) self.prefixes = defaultdict(int) self.times = [] self._cached_sorts = {} self.start_ts = None self.last_ts = None self.last_entry = None self.prefix_delim = prefix_delim self.redis_version = redis_version self.line_re = line_re_24 if self.redis_version < 2.5 else line_re_26 def _record_duration(self, entry): ts = float(entry['timestamp']) * 1000 * 1000 # microseconds if not self.start_ts: self.start_ts = ts self.last_ts = ts duration = ts - self.last_ts if self.redis_version < 2.5: cur_entry = entry else: cur_entry = self.last_entry self.last_entry = entry if duration and cur_entry: self.times.append((duration, cur_entry)) self.last_ts = ts def _record_command(self, entry): self.commands[entry['command']] += 1 def _record_key(self, key): self.keys[key] += 1 parts = key.split(self.prefix_delim) if len(parts) > 1: self.prefixes[parts[0]] += 1 @staticmethod def _reformat_entry(entry): max_args_to_show = 5 output = '"%(command)s"' % entry if entry['key']: output += ' "%(key)s"' % entry if entry['args']: arg_parts = entry['args'].split(' ') ellipses = ' ...' if len(arg_parts) > max_args_to_show else '' output += ' %s%s' % (' '.join(arg_parts[0:max_args_to_show]), ellipses) return output def _get_or_sort_list(self, ls): key = id(ls) if not key in self._cached_sorts: sorted_items = sorted(ls) self._cached_sorts[key] = sorted_items return self._cached_sorts[key] def _time_stats(self, times): sorted_times = self._get_or_sort_list(times) num_times = len(sorted_times) percent_50 = sorted_times[int(num_times / 2)][0] percent_75 = sorted_times[int(num_times * .75)][0] percent_90 = sorted_times[int(num_times * .90)][0] percent_99 = sorted_times[int(num_times * .99)][0] return (("Median", percent_50), ("75%", percent_75), ("90%", percent_90), ("99%", percent_99)) def _heaviest_commands(self, times): times_by_command = defaultdict(int) for time, entry in times: times_by_command[entry['command']] += time return self._top_n(times_by_command) def _slowest_commands(self, times, n=8): sorted_times = self._get_or_sort_list(times) slowest_commands = reversed(sorted_times[-n:]) printable_commands = [(str(time), self._reformat_entry(entry)) \ for time, entry in slowest_commands] return printable_commands def _general_stats(self): total_time = (self.last_ts - self.start_ts) / (1000*1000) return ( ("Lines Processed", self.line_count), ("Commands/Sec", '%.2f' % (self.line_count / total_time)) ) def process_entry(self, entry): self._record_duration(entry) self._record_command(entry) if entry['key']: self._record_key(entry['key']) def _top_n(self, stat, n=8): sorted_items = sorted(stat.iteritems(), key = lambda x: x[1], reverse = True) return sorted_items[:n] def _pretty_print(self, result, title, percentages=False): print title print '=' * 40 if not result: print 'n/a\n' return max_key_len = max((len(x[0]) for x in result)) max_val_len = max((len(str(x[1])) for x in result)) for key, val in result: key_padding = max(max_key_len - len(key), 0) * ' ' if percentages: val_padding = max(max_val_len - len(str(val)), 0) * ' ' val = '%s%s\t(%.2f%%)' % (val, val_padding, (float(val) / self.line_count) * 100) print key,key_padding,'\t',val print def print_stats(self): self._pretty_print(self._general_stats(), 'Overall Stats') self._pretty_print(self._top_n(self.prefixes), 'Top Prefixes', percentages = True) self._pretty_print(self._top_n(self.keys), 'Top Keys', percentages = True) self._pretty_print(self._top_n(self.commands), 'Top Commands', percentages = True) self._pretty_print(self._time_stats(self.times), 'Command Time (microsecs)') self._pretty_print(self._heaviest_commands(self.times), 'Heaviest Commands (microsecs)') self._pretty_print(self._slowest_commands(self.times), 'Slowest Calls') def process_input(self, input): for line in input: self.line_count += 1 line = line.strip() match = self.line_re.match(line) if not match: if line != "OK": self.skipped_lines += 1 continue self.process_entry(match.groupdict()) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument( 'input', type = argparse.FileType('r'), default = sys.stdin, nargs = '?', help = "File to parse; will read from stdin otherwise") parser.add_argument( '--prefix-delimiter', type = str, default = ':', help = "String to split on for delimiting prefix and rest of key", required = False) parser.add_argument( '--redis-version', type = float, default = 2.6, help = "Version of the redis server being monitored", required = False) args = parser.parse_args() counter = StatCounter(prefix_delim = args.prefix_delimiter, redis_version = args.redis_version) counter.process_input(args.input) counter.print_stats()说明 以上脚本来自 redis-faina。 - 使用
python redis-faina imonitorOut.txt命令解析监控数据。其中imonitorOut.txt为本文示例中保存的监控数据。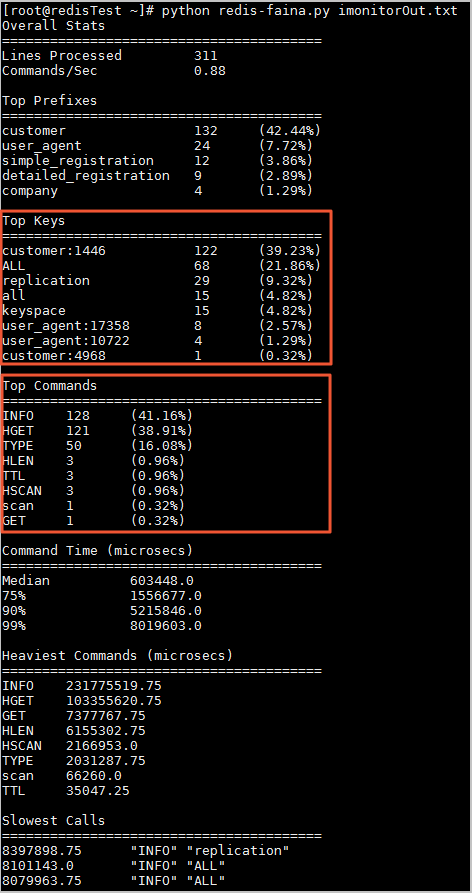 说明 在以上分析结果中, Top Keys显示该时间段内请求次数最多的键, Top Commands显示使用最频繁的命令。您可以根据分析情况解决热点key问题。
说明 在以上分析结果中, Top Keys显示该时间段内请求次数最多的键, Top Commands显示使用最频繁的命令。您可以根据分析情况解决热点key问题。
