云数据库 RDS 版
- 十分钟了解RDS
- 云数据库RDS简介
- 云数据库RDS价格
- RDS for MySQL 快速入门
- RDS for MySQL 用户指南
- RDS for SQL Server 快速入门
- RDS for SQL Server 用户指南
- RDS for PostgreSQL 快速入门
- RDS for PostgreSQL 用户指南
- RDS for PPAS 快速入门
- RDS for PPAS 用户指南
- RDS for MariaDB TX 快速入门
- RDS for MariaDB TX 用户指南
-
时空数据库
- 简介
- 模型
- 使用进阶
- Raster SQL参考
-
PointCloud SQL参考
- 构造函数
- 属性函数
-
对象操作
- ST_compress
- ST_unCompress
- ST_union
- ST_explode
- ST_patchAvg
- ST_patchMax
- ST_patchMin
- ST_patchAvg
- ST_patchMax
- ST_patchMin
- ST_filterGreaterThan
- ST_filterLessThan
- ST_filterEquals
- ST_filterBetween
- ST_pointN
- ST_isSorted
- ST_sort
- ST_range
- ST_setPcid
- ST_transform
- ST_envelopeGeometry
- ST_boundingDiagonalGeometry
- OGC WKB操作
- 空间关系判断
- 空间处理
-
Trajectory SQL参考
- 基本概念
- 构造函数
- 编辑与处理函数
- 属性元数据
- 事件函数
-
属性函数
- ST_startTime
- ST_endTime
- ST_trajectorySpatial
- ST_trajectoryTemporal
- ST_trajAttrs
- ST_attrIntMax
- ST_attrIntMin
- ST_attrIntAverage
- ST_attrFloatMax
- ST_attrFloatMin
- ST_attrFloatAverage
- ST_leafType
- ST_leafCount
- ST_Duration
- ST_timeAtPoint
- ST_pointAtTime
- ST_ velocityAtTime
- ST_accelerationAtTime
- ST_timeToDistance
- ST_timeAtDistance
- ST_cumulativeDistanceAtTime
- ST_timeAtCumulativeDistance
- ST_subTrajectory
- ST_subTrajectorySpatial
- ST_samplingInterval
- ST_length
- ST_trajAttrsAsText
- ST_trajAttrsAsInteger
- ST_trajAttrsAsDouble
- ST_trajAttrsAsBool
- ST_trajAttrsAsTimestamp
- ST_attrIntFilter
- ST_attrFloatFilter
- ST_attrTimestampFilter
- ST_attrNullFilter
- ST_attrNotNullFilter
- 空间关系判断
- 空间处理
- 空间统计
- 时空关系判断
- 时空处理
- 时空统计
- 距离测量
- Trajectory 最佳实践
- Trajecotry 常见问题
- 性能白皮书
- 安全白皮书
- 最佳实践
-
API参考
- API概览
- 使用API
-
实例管理
- CreateDBInstance
- DeleteDBInstance
- RestartDBInstance
- RenewInstance
- DescribeDBInstanceAttribute
- DescribeDBInstances
- ModifyDBInstanceSpec
- DescribeRegions
- DescribeDBInstanceHAConfig
- MigrateToOtherZone
- PurgeDBInstanceLog
- UpgradeDBInstanceEngineVersion
- ModifyDBInstanceDescription
- ModifyDBInstanceMaintainTime
- ModifyDBInstanceHAConfig
- SwitchDBInstanceHA
- CreateReadOnlyDBInstance
- DestroyDBInstance
- ModifyDBInstanceDelayReplicationTime
- CloudDBA数据库性能优化
- 数据库管理
- 数据库代理
- 账号管理
- 安全管理
- 网络管理
- 日志管理
- 备份恢复
- SQL Server备份文件上云
- 监控管理
- 参数管理
- 数据迁移
- 标签管理
- RAM资源授权
- 附表
- SDK参考
-
常见问题
- RDS简介
- 购买
-
参数/性能
- 解决CPU、内存、空间、IOPS使用率偏高的问题
- RDS for MySQL/MariaDB CPU使用率高的原因和解决方法
- MySQL IOPS 使用率高的原因和解决方法
- RDS for MySQL表上Metadata lock的处理
- RDS for MySQL行锁等待和行锁等待超时的处理
- RDS for MySQL表级锁等待
- RDS for MySQL管理长时间执行的查询
- RDS for MySQL查询缓存(Query Cache)的设置和使用
- RDS for MySQL如何保证数据库字符编码正确
- RDS for MySQL收集表的统计信息
- RDS for MySQL字符集相关说明
- RDS for MySQL如何修改为utf8mb4字符集
- RDS for MySQL查看和设置时区
- RDS for MySQL无法查询performance_schema的原因
- RDS for MySQL Online DDL 使用
- RDS for MySQL默认关闭MyISAM引擎
- RDS for MySQL各timeout参数的设置
- RDS for SQL Server查看当前连接以及其执行的SQL
- RDS for SQL Server查看锁情况
- RDS for SQL Server死锁处理方法
- RDS for SQL Server CPU使用率高问题排查
- RDS for SQL Server查看常用参数值
- RDS for SQL Server常用视图
- RDS for SQL Server字符集修改
- PostgreSQL/PPAS CPU使用率高的原因及解决办法
- RDS for PostgreSQL查看数据库内核小版本
- RDS访问实例诊断报告
- 监控项列表
- 为什么SQL语句在ECS上查询比RDS上快
- 迁入RDS后数据库变慢的分析
- 如何提升RDS响应速度
- 升级实例底层网络架构的意义及对业务的影响是什么?
- RDS MySQL 全文检索相关问题的处理
-
数据备份/恢复
- RDS for MySQL 物理备份文件恢复到自建数据库
- RDS for MySQL 逻辑备份文件恢复到自建数据库
- RDS for MySQL SQL审计查询记录返回0的原因
- RDS for MySQL查看增量数据的方法
- RDS for MySQL mysqldump选项设置
- RDS for MySQL使用load data local infile导入数据
- 使用mysqldump迁移数据
- Binlog常见问题
- RDS for MySQL通过mysqlbinlog查看binlog日志
- MySQL Binlog日志的生成和清理规则
- RDS for MySQL远程获取Binlog
- 如何进行RDS(mysql类型)针对数据库级别的备份及回滚
- RDS for MySQL备份文件下载工具
- RDS for SQL Server/MySQL实例备份单个数据库
- 如何恢复误删除的数据
- RDS for MySQL 5.6如何恢复单个数据库
- RDS for SQL Server收缩事务日志
- RDS for SQL Server单库恢复
- Linux平台使用wget工具下载备份文件
- Windows下解压MySQL备份文件
- 将自建数据库迁移至RDS
-
网络/IP
- 解决无法连接实例问题
- RDS实例如何变更虚拟交换机VSwitch
- RDS实例如何变更VPC
- RDS 实例如何在经典网络和 VPC 网络之间互相切换
- RDS for MySQL 连接数满情况的处理
- RDS for MySQL如何终止会话
- JAVA连接RDS for MySQL的测试程序
- JAVA连接RDS for SQL Server
- RDS for PostgreSQL/PPAS 如何定位本地 IP
- SQL Server如何定位IP地址
- RDS for MySQL或MariaDB TX如何定位本地公网IP地址
- RDS for PostgreSQL 连接数满情况的处理
- 应用程序是否需要支持自动重连数据库
- 阿里云在RDS遭受攻击时提供什么安全服务
- 外部服务器能否访问阿里云的RDS?
- RDS数据库实例授权其他客户登录方法
- 为什么无法连接到RDS实例?
- ECS和RDS的网络类型不同,如何通过内网互通?
- ECS和RDS位于不同VPC,如何内网互通?
- ECS和RDS位于不同地域,如何通过内网互通?
- ECS如何访问另一个账号下的RDS?
-
数据库/账号/表
- 如何连接RDS数据库
- RDS for MySQL使用utf8mb4字符集存储emoji表情
- RDS for MySQL表分区的限制
- RDS for MySQL 5.6 版本GTID特性对临时表限制的处理
- RDS for MySQL的单表尺寸限制
- RDS for MySQL引擎表索引方式更改为Hash无效原因
- RDS for MySQL auto_increment自增字段相关参数
- RDS for MySQL数据库自增列不连续的问题
- RDS for MySQL函数group_concat相关问题
- RDS for MySQL查看表的主键字段的方法
- RDS for MySQL排序分页查询数据顺序错乱的处理
- RDS for SQL Server如何修改schema为dbo
- RDS for SQL Server添加作业计划
- RDS for SQL Server手动执行作业及查看执行记录
- RDS for SQL Server批量导入数据
- RDS for PostgreSQL 9.4中如何支持jsonb_set等新的 jsonb函数
- RDS for PostgreSQL用户权限设置
- RDS for PostgreSQL使用中文分词
- RDS for PostgreSQL跨库查询
- RDS for PPAS如何管理插件
- 如何快速对比测试环境和开发环境的表结构?
- RDS for SQL Server创建聚簇索引注意事项
- 功能/付费方式
- 实例规格/版本
-
空间/内存
- 新购MySQL实例的存储空间占用说明
- 释放MySQL表空间
- MySQL 实际内存分配情况介绍
- 云盘如何变更为本地盘
- 解决MySQL实例空间满自动锁问题
- MySQL数据文件导致实例空间满的解决办法
- MySQL Binlog文件导致实例空间满的解决办法
- MySQL临时文件导致实例空间满的解决办法
- MySQL系统文件导致实例空间满的解决办法
- RDS MySQL 空间问题的原因和解决
- RDS for MySQL备份、SQL审计相关问题
- 解决SQL Server实例空间满自动锁的问题
- RDS for SQL Server如何查看实例、数据库及表占用的空间大小
- SQL Server数据库空间查看工具
- RDS for SQL Server查看内存占用情况
- RDS for SQL Server 回收表空间
- PostgreSQL/PPAS磁盘空间占用剧增后下降情况解析
- 使用OSS扩展PostgreSQL/PPAS的表空间
- RDS for PPAS是否支持表空间维护
- 读写分离/只读实例
-
错误代码
- RDS for MySQL权限问题(错误代码:1227,1725)
- mysqld:Sort aborted:Server shutdown in progress错误处理
- 安装ThinkSNS网站调用RDS数据库提示OPERATION need to be executed set by ADMIN
- The maximum column size is 767 bytes错误处理
- Cannot add foreign key constraint错误处理
- r'错误处理...
- the table '/home/mysql/xxxx/xxxx/#tab_name' is full错误处理
- Out of resources when opening file './xxx.MYD' (Errcode: 24)错误处理
- The Changes you have made require the following table错误处理
- There are 2 other sessions using the database错误处理
- relation "xxx" already exists错误处理
- Caused By: ERROR: syntax error at end of input错误处理
- Unknown MySQL server host错误处理
- 临时实例报错The operation is not permitted due to no backup处理
- 0038或10060或110)...
- 000): #RDS00ip not in whitelist...
- ERROR 1045 (28000): Access denied for user ‘XXX’@’XXX’
- 证实例名称是否正确并且 SQL Server 已配置为允许远程连接。错误: 10060或258...
- DTS相关问题
- DMS相关问题
- 视频专区
- 相关协议
- 技术运维问题
- 产品使用问题
解析SQL Server 2012常用的分析函数
分析函数CUME_DIST
微软的定义:
计算某个值在SQL Server 2012中的一组值内的累积分布。CUME_DIST计算某指定值在一组值中的相对位置。对于行r,假定采用升序,r的CUME_DIST是值低于或等于r的值的行数除以在分区或查询结果集中求出的行数。
函数解析:
执行如下代码,构造一组数据。
- DECLARE
- @analytic TABLE(
- name varchar(35) ,
- dept varchar(35),
- salary money
- )
- INSERT INTO @analytic
- VALUES
- --bd
- ('andy01','bd',15000),
- ('andy02','bd',12000),
- ('andy03','bd',12000),
- ('andy04','bd',10000),
- ('andy05','bd',8000),
- --ca
- ('andy06','ca',20000),
- ('andy07','ca',18000),
- ('andy08','ca',18000),
- ('andy09','ca',15000),
- ('andy10','ca',12000),
- ('andy11','ca',12000),
- ('andy12','ca',10000),
- ('andy13','ca',8000),
- ('andy14','ca',8000),
- ('andy15','ca',8000)
- SELECT
- dept,name ,salary,
- CUME_DIST() OVER(PARTITION BY dept ORDER BY salary) AS cume_dist_
- FROM @analytic
- ORDER BY dept,salary DESC
返回结果如下:
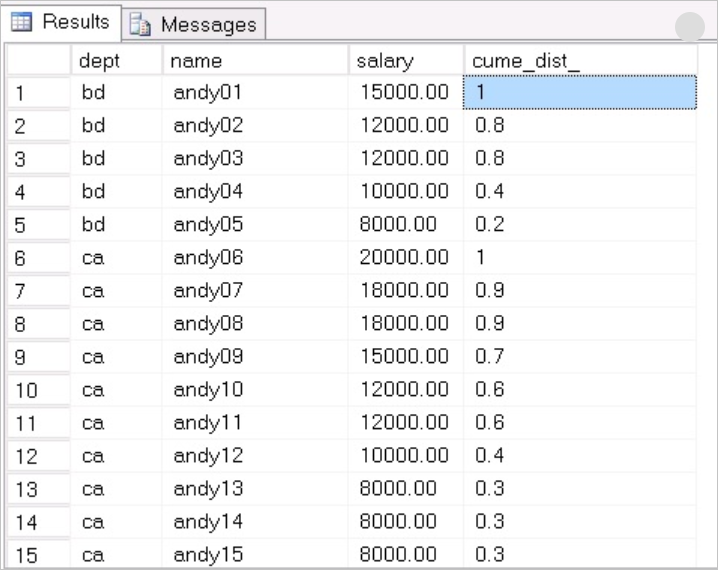
示例解析:
按照dept分组,根据salary逻辑排序,针对每一个分组里的每一个值,计算在该分组下等于或者小于自己的salary的分布的百分比。举个例子,bd部门的andy02,salary为12000,那么等于或者小于这个12000的有4条,总共5条记录,因此那么CUME_DIST()=4/5=0.8。 同理,其它也是这样计算。
分析函数LAST_VALUE
微软的定义:
返回SQL Server 2012中有序值集中的最后一个值。
函数解析:
执行如下代码,构造一组数据。
- DECLARE
- @analytic TABLE(
- name varchar(35) ,
- dept varchar(35),
- salary money ,
- hiredate date
- )
- INSERT INTO @analytic
- VALUES
- --bd
- ('andy01','bd',15000,'2002-01-09'),
- ('andy02','bd',12000,'2003-01-09'),
- ('andy03','bd',12000,'2003-02-09'),
- ('andy04','bd',10000,'2005-05-09'),
- ('andy05','bd',8000,'2003-06-09'),
- --ca
- ('andy06','ca',20000,'2003-01-09'),
- ('andy07','ca',18000,'2005-02-09'),
- ('andy08','ca',18000,'2005-03-09'),
- ('andy09','ca',15000,'2004-01-09'),
- ('andy10','ca',12000,'2003-06-09'),
- ('andy11','ca',12000,'2002-09-09'),
- ('andy12','ca',10000,'2003-07-09'),
- ('andy13','ca',8000,'2003-08-09'),
- ('andy14','ca',8000,'2003-11-09'),
- ('andy15','ca',8000,'2003-01-09')
- SELECT
- dept,name ,salary,hiredate,
- LAST_VALUE(hiredate) OVER(PARTITION BY dept ORDER BY salary) AS last_value_
- FROM @analytic
返回结果如下:
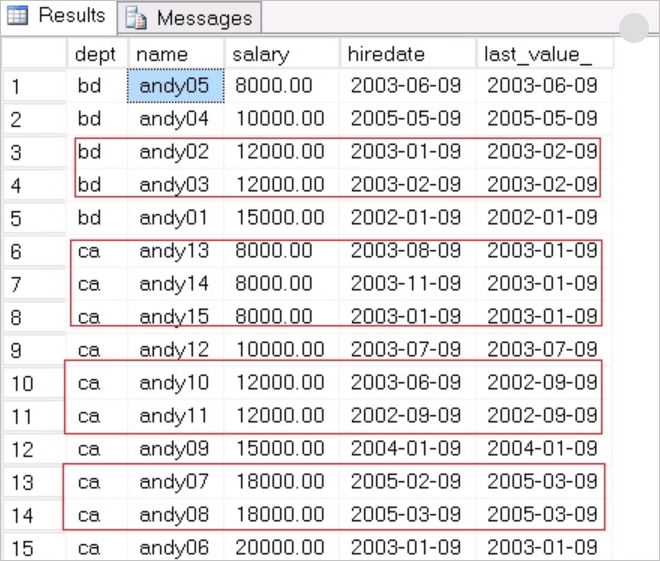
示例解析:
按照OVER子句中ORDER BY根据salary排序,取salary最后行的hiredate值作为最后的LAST VALUE,重点在于当salary有相同的值时,需要取根据salary排序后的最后一条记录作为其他的LAST VALUE。
分析函数FIRST_VALUE
微软的定义:
返回SQL Server 2012中有序值集中的第一个值。
函数解析:
从微软的定义来看,FIRST_VALUE似乎跟LAST_VALUE是相反的含义,但实际并非如此。
执行如下代码,构造一组数据。
- DECLARE
- @analytic TABLE(
- name varchar(35) ,
- dept varchar(35),
- salary money ,
- hiredate date
- )
- INSERT INTO @analytic
- VALUES
- --bd
- ('andy01','bd',15000,'2002-01-09'),
- ('andy02','bd',12000,'2003-01-09'),
- ('andy03','bd',12000,'2003-02-09'),
- ('andy04','bd',10000,'2005-05-09'),
- ('andy05','bd',8000,'2003-06-09'),
- --ca
- ('andy06','ca',20000,'2003-01-09'),
- ('andy07','ca',18000,'2005-02-09'),
- ('andy08','ca',18000,'2005-03-09'),
- ('andy09','ca',15000,'2004-01-09'),
- ('andy10','ca',12000,'2003-06-09'),
- ('andy11','ca',12000,'2002-09-09'),
- ('andy12','ca',10000,'2003-07-09'),
- ('andy13','ca',8000,'2003-08-09'),
- ('andy14','ca',8000,'2003-11-09'),
- ('andy15','ca',8000,'2003-01-09')
- SELECT
- dept,name ,salary,hiredate,
- FIRST_VALUE(name) OVER(PARTITION BY dept ORDER BY salary) AS first_value_
- FROM @analytic
返回结果如下:
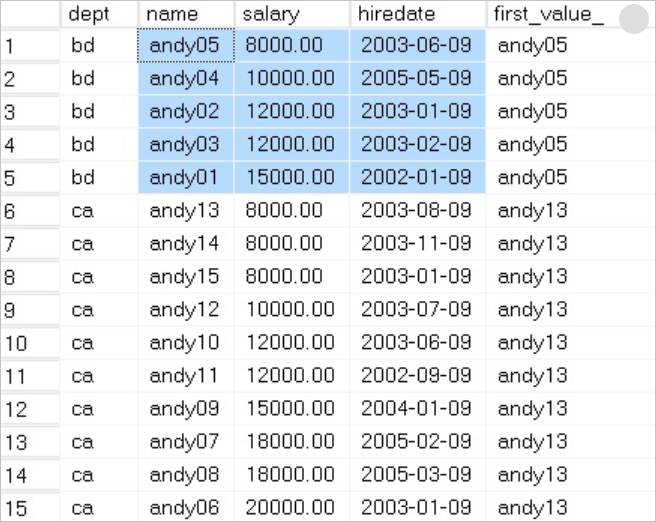
示例分析:
显然,这个与LAST_VALUE并不是相反的含义。OVER子句根据ORDER BY来排序,按dept分组来确定这个分组的第一个值,而不是根据salary的值来确定的,所以与LAST_VALUE是不一样的。将FIRST_VALUE(name)修改为FIRST_VALUE(hiredate)后,对比看得更清楚,这个很有蒙蔽性。
分析函数LEAD
微软的定义:
访问相同结果集的后续行中的数据,而不使用SQL Server 2012中的自联接。LEAD以当前行之后的给定物理偏移量来提供对行的访问。在SELECT语句中使用此分析函数可将当前行中的值与后续行中的值进行比较。
函数解析:
执行如下代码,构造一组数据。
- DECLARE
- @analytic TABLE(
- name varchar(35) ,
- dept varchar(35),
- salary money ,
- hiredate date
- )
- INSERT INTO @analytic
- VALUES
- --bd
- ('andy01','bd',15000,'2002-01-09'),
- ('andy02','bd',12000,'2003-01-09'),
- ('andy03','bd',12000,'2003-02-09'),
- ('andy04','bd',10000,'2005-05-09'),
- ('andy05','bd',8000,'2003-06-09'),
- --ca
- ('andy06','ca',20000,'2003-01-09'),
- ('andy07','ca',18000,'2005-02-09'),
- ('andy08','ca',18000,'2005-03-09'),
- ('andy09','ca',15000,'2004-01-09'),
- ('andy10','ca',12000,'2003-06-09'),
- ('andy11','ca',12000,'2002-09-09'),
- ('andy12','ca',10000,'2003-07-09'),
- ('andy13','ca',8000,'2003-08-09'),
- ('andy14','ca',8000,'2003-11-09'),
- ('andy15','ca',8000,'2003-01-09')
- SELECT
- dept,name,hiredate,salary,
- LEAD(salary,1,0) OVER(PARTITION BY dept ORDER BY salary) AS lead_,
- (LEAD(salary,1,0) OVER(PARTITION BY dept ORDER BY salary)-salary) AS diff_salary
- FROM @analytic
返回结果如下:
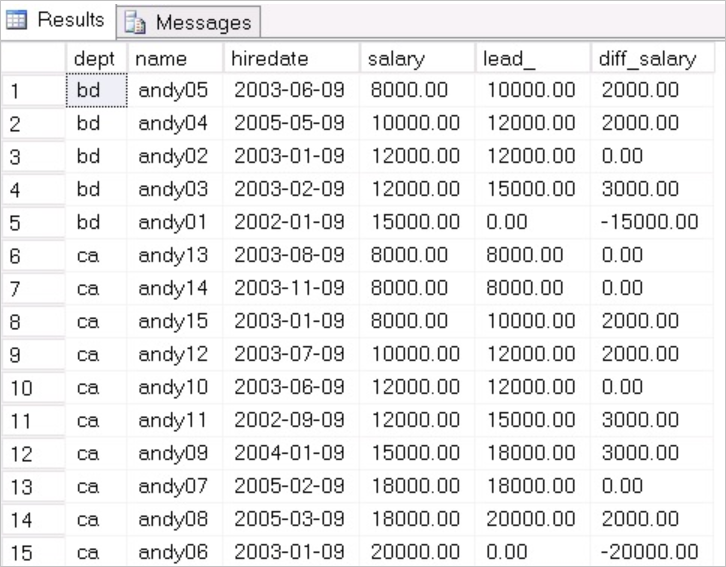
示例分析:
按照dept分区,根据salary排序,比较当前记录和后一条记录(偏移量为1)的salary值的差值,这个非常实用。
