对于大数据量、较复杂的时空查询,Ganos可直接利用PG并行查询的能力从而加速时空查询。
并行查询原理
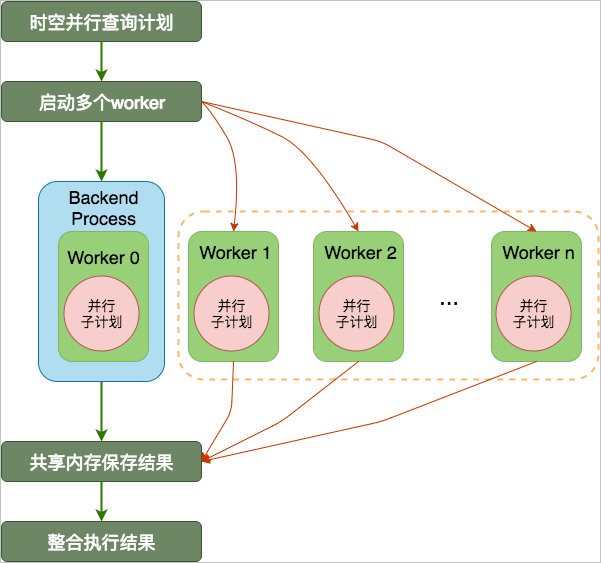
PG并行查询是表级的并行,其并行查询示意图如下。
注意事项
- 并行查询的worker数量越大,worker数越多,查询时CPU负载越重,对于CPU负载本身较重的场景建议woker数量设置为2较合适,即max_parallel_workers_per_gather=2。
- 对于服务器内存有限的高并发访问,开启并行查询时,需要控制参数work_men(min 64KB),确保并发访问数量乘以并行worker数量乘以work_mem不超过服务器内存的60%。
使用方法
开启Ganos并行查询的方法如下:
- 修改PostgreSQL配置文件postgresql.conf,启用并行查询参数。
- 开启max_parallel_workers参数,设置能够开启的并行worker总数量,须小于max_worker_processes的值,通常为8-32。
- 开启max_parallel_workers_per_gather参数,设置单个查询gahter最大并行度,须小于max_parallel_workers的值,通常为2-4。
- 如果要开启强制并行,须将force_parallel_mode设置为on。
- 通过执行SQL语句控制单个表的并行粒度:alter table table_name set (parallel_workers=n)。
说明 “n”代表并行worker数,该值可参见max_parallel_workers_per_gather。
- 提高Ganos相关函数的cost成本。
在创建Ganos模块扩展时,通常默认有个函数cost成本,如果表数据量较小,但函数属于计算密集,并且适合开启并行执行,此时默认不会开启并行查询,需要提高函数的cost成本后才能开启并行查询。
