TVS文档
SpeechRecognizer接口
AVS官方文档链结: https://developer.amazon.com/de/docs/alexa-voice-service/speechrecognizer.html?v=1_0
每个用户的问句都会使用到SpeechRecognizer。这是TmallGenie Voice Service (TVS)的核心接口。这个接口透出了用以取得用户语音与提示客户端TmallGenie需要额外语音输入时的指令与事件。
此外,这个接口也允许你的客户端告知TVS此次交互是如何被启动的(持续按压、点击、唤醒词),并为你的产品选择合适的ASR profile,这能让精灵服务更加了解用户的语音特性并处理的更加精准。
状态图
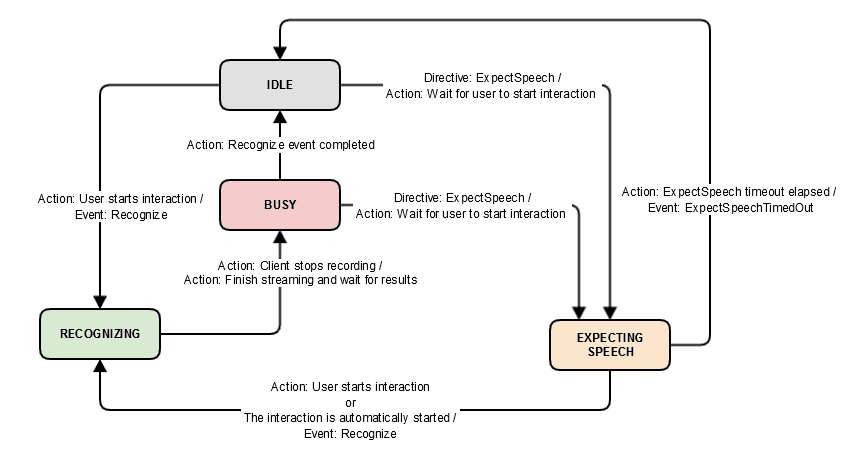
SpeechRecognizer上下文
TmallGenie期望所有有使用唤醒词的客户端都能上报目前所使用的唤醒词。
Sample Message
{
"header": {
"namespace": "SpeechRecognizer",
"name": "RecognizerState"
},
"payload": {
"wakeword": "tian mao jing ling"
}
}
Payload参数
| 参数 | 描述 | 型态 |
|---|---|---|
| wakeword | 用以识别目前的唤醒词。 允许值 : “tian mao jing ling” |
字串 |
Recognize事件
Recognize事件是用来将用户语音传送给TVS,且会将此语音转为一到多个下发给设备的指令。此事件必须以multipart信息的方式发送:第一部分是一个JSON对象,第二部分是由设备麦克风取得的音频二进制内容。因此,整个 Recognize 事件报文与一般文件上传请求是非常类似的。
在与TVS的交互启动后,麦克风必须持续开启直到用户手动关闭麦克风,此时即应使用此事件来上传音频内容。
我们用profile参数与initiator对象告知TmallGenie应该使用哪个ASR profile能最好的解析所捕捉到的音频,还有此次与TmallGenie的交互是如何被启动的。
所有捕捉到并发送给TVS的音频应该要使用以下方式编码:
-
16bit Linear PCM
-
16kHz sample rate
-
Single channel
-
Little endian byte order
API URL
/v1/avs/speechrecognizer/recognize
Sample Message
{
? "context": [
// This is an array of context objects that are used to communicate the
// state of all client components to Alexa. See Context for details.
],
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "Recognize",
"messageId": "{{STRING}}",
"dialogRequestId": "{{STRING}}"
},
"payload": {
"profile": "{{STRING}}",
"format": "{{STRING}}",
"initiator": {
"type": "{{STRING}}",
"payload": {
"wakeWordIndices": {
"startIndexInSamples": {{LONG}},
"endIndexInSamples": {{LONG}}
},
"token": "{{STRING}}"
}
}
}
}
}
Binary Audio Attachment
每个 Recognize 事件都需要有一个对应的二进制音频附件作为multipart报文中的其中一部分。对于每个二进制音频附件都需要有以下headers:
Content-Disposition: form-data; name="audio"
Content-Type: application/octet-stream
{{BINARY AUDIO ATTACHMENT}}
上下文
此事件需要产品将所有客户端组件的状态置于context对象中上报给TVS。
Header参数
| 参数 | 描述 | 型态 |
|---|---|---|
| messageId | 用以代表一个特定message的唯一ID。 | 字串 |
| dialogRequestId | 由客户端为每一个发送给TVS的 Recognize 事件所生成的唯一ID。此参数用以将TVS所下发的指令与某个特定 Recognize 事件。 |
字串 |
Payload参数
| 参数 | 描述 | 型态 |
|---|---|---|
| profile | 您产品所使用的ASR profile。TVS支持三类不同的ASR profile。 目前仅需实际支持 NEAR_FIELD 允許值: CLOSE_TALK 、 NEAR_FIELD 与 FAR_FIELD |
字串 |
| format | 标明所捕捉音频的格式。 允許值: AUDIO_L16_RATE_16000_CHANNELS_1 ? |
字串 |
| initiator | 让TmallGenie知道这次的交互是如何被启动的。当此次交互是由用户发起时,此对象必须包含在此事件的payload中。如果 initiator 出现在 ExpectSpeech 指令里,则其必须在后续的 Recognize 事件中原样返回。如果 initiator 没有在 ExpectSpeech 指令中,则其后续的 Recognize 事件中也不该包含此字段。 |
对象 |
| initiator.type | 允许值:PRESS_AND_HOLD , TAP , and WAKEWORD. |
字串 |
| initiator.payload | 包含关于此initiator的信息 | 对象 |
| initiator.payload.wakeWordIndices | 当initiator.type为WAKEWORD时需要此字段 | 对象 |
| initiator.payload.wakeWordIndices.startIndexInSamples | 表示在音频流中唤醒词是从哪边开始的(根据采样)。起始index应该精准到在唤醒词侦测到的50ms内。 | 长整数 |
| initiator.payload.wakeWordIndices.endIndexInSamples | 表示在音频流中唤醒词是从哪边结束的(根据采样)。结束index应该精准到在唤醒词结束后的150ms内。 | 长整数 |
| initiator.payload.token | An opaque string. This value is only required if present in the payload of a preceding ExpectSpeech ?directive. |
字串 |
注意:宝马使用的initiator与profile是:
- initiator: TAP
- profile: NEAR_FIELD
- 宝马没有处理StopCapture指令
Profiles
| 值 | 最佳聆听距离 |
|---|---|
| CLOSE_TALK | 0到75公分 |
| NEAR_FIELD | 0到1.5公尺 |
| FAR_FIELD | 0到6公尺以上 |
Initiator
| 值 | 描述 | 支持的profiles | 是否有StopCapture指令 | 是否需要唤醒词验证 | 是否需要给予唤醒词索引 |
|---|---|---|---|---|---|
| PRESS_AND_HOLD | 音频流由按压按钮开始,并透过释放按钮结束 | CLOSE_TALK |
N | N | N |
| TAP | 音频流由点击并释放按钮开始,当收到StopCapture指令时结束 | NEAR_FIELD 、FAR_FIELD |
Y | N | N |
| WAKEWORD | 音频流由侦测到唤醒词开始,当收到StopCapture指令时结束 | NEAR_FIELD 、 FAR_FIELD |
Y | Y | Y |
ExpectSpeech指令
当TmallGenie需要额外的信息来满足用户的请求时,TmallGenie会回复ExpectSpeech指令。此指令告知客户端需要打开麦克风并开始给予用户语音的音频流。如果麦克风在一定的超时时长内没有打开的话,则客户端必须上报ExpectSpeechTimedOut事件给TVS。
在与TmallGenie进行多轮交互的过程中,你的设备将会收到至少一个的ExpectSpeech指令来要求客户端开始聆听用户语音。在这个情况下,其后续的Recognize事件中的initiator对象必须使用包含在ExpectSpeech指令的payload中所包含的initiator对象,并直接回传给TmallGenie。如果ExpectSpeech指令的payload中没有initiator,则后续的Recognize事件也 不 应该包含initiator。
Sample Message
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "ExpectSpeech",
"messageId": "{{STRING}}",
"dialogRequestId": "{{STRING}}"
},
"payload": {
"timeoutInMilliseconds": {{LONG}},
"initiator": {{STRING}}
}
}
}
Header参数
| 参数 | 描述 | 型态 |
|---|---|---|
| messageId | 用以代表一个特定message的唯一ID。 | 字串 |
| dialogRequestId | 用以将指令与一个特定Recognize事件关连的唯一ID。 |
字串 |
Payload参数
| 参数 | 描述 | 型态 |
|---|---|---|
| timeoutInMilliseconds | 指定了你的客户端应该在多长的时间内应该开麦并开始发送用户语音音频流给TVS。如果麦克风在指定时间内没有打开,则客户端必须上报ExpectSpeechTimedOut事件。此行为的主要用例是PRESS_AND_HOLD类型的客户端实现。 | 长整数 |
| initiator | An opaque string. 如果出现的话,则其内容必需在后续的Recognize事件中返回传给TVS | 字 |
StopCapture指令
此指令会在TVS已经识别到用户意图或侦测到用户语音以结束时下发给客户端,以要求客户端停止撷取用户语音。当客户端此指令时,客户端必须立刻停止麦克风并停止聆听用户语音。
注意:StopCapture 会由下行通道下发到客户端,此时用户语音还有可能持续的由客户端发送给TVS。如果希望能接收到 StopCapture 指令的话,你必须在你的 Recognize 指令中使用支持云端VAD的 profile,像是 NEAR_FIELD 或 FAR_FIELD。
版本支持
- HTTP1.1不支持
- HTTP/2需不支持
Sample Message
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "StopCapture",
"messageId": "{{STRING}}",
"dialogRequestId": "{{STRING}}"
},
"payload": {
}
}
}
Header参数
| 参数 | 描述 | 型态 |
|---|---|---|
| messageId | 用以代表一个特定message的唯一ID。 | 字串 |
| dialogRequestId | 用以将指令与一个特定Recognize事件关连的唯一ID。 |
字串 |
ExpectSpeechTimeOut事件
此事件必须在 ExpectSpeech 指令收到之后,但客户端没有在指定的时间内收到用户问句时上报给TVS。
版本支持
- HTTP1.1不支持
- HTTP/2需不支持
Sample Message
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "ExpectSpeechTimedOut",
"messageId": "{{STRING}}",
},
"payload": {
}
}
}
ExtRecognizeResult[定制]
带屏设备可以展示ASR结果给用户,该指令标识ASR的实时结果。
Sample Message
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "ExtRecognizeResult",
"messageId": "{{STRING}}",
"dialogRequestId": "{{STRING}}"
},
"payload": {
"text": "{{STRING}}",
"end": "{{BOOL}}"
}
}
}
Header参数
| 参数 | 描述 | 型态 |
|---|---|---|
| messageId | 用以代表一个特定message的唯一ID。 | 字串 |
| dialogRequestId | 用以将指令与一个特定Recognize事件关连的唯一ID。 |
字串 |
Payload参数
| 参数 | 描述 | 型态 |
|---|---|---|
| end | true表示为最终结果,false表示是中间结果 | Bool |
| text | ASR结果。如果最终结果为空,表示ASR无法识别出文本。 | String |
